[Are you really interested in learning how to Write a Search Engine from Scratch? Click this link and register your interest for my book about how to do so.][1]
This is part 5 of a 5 part series.
[Part 1][2] – [Part 2][3] – [Part 3][4] – [Part 4][5] – [Part 5][6] – [Downloads/Code][7]
So we need to convert the indexer to a method that wont consume as much memory. Looking at how it works now we can determine a few areas that could be improved before we implement out new method.``` public function index(array $documents) { $documenthash = array(); // so we can process multiple documents faster
foreach($documents as $document) { $con = $this->_concordance($this->_cleanDocument($document)); $id = $this->documentstore->storeDocument(array($document));
foreach($con as $word => $count) { if(!$this->_inStopList($word)) { if(!array_key_exists($word,$documenthash)) { $ind = $this->index->getDocuments($word); $documenthash[$word] = $ind; }
// Rank the Document
$rank = $this->ranker->rankDocument($word,$document);
if(count($documenthash[$word]) == 0) {
$documenthash[$word] = array(array($id,$rank,0));
}
else {
$documenthash[$word][] = array($id,$rank,0);
}
} } }
foreach($documenthash as $key => $value) { usort($value, array($this->ranker, ‘rankIndex’)); $this->index->storeDocuments($key,$value); } return true; }
The above is our index method. The first thing I noticed is that during the main foreach over the documents we can free memory by unsetting each document after it has been processed. Doing this is a fairly simple change to the foreach loop. We just change the foreach loop to the following,```
for($i=0;$i<$cnt = count($documents); $i++) {
$document = $documents[$i];
unset($documents[$i]);
We are now unsetting everything as we go. This should free some memory as we go along. The next thing to do is convert it over to storing the index on disk rather then memory. I was thinking about this for a while and came up with the idea that for each new word we find we load the existing index from disk and flush it to a scratchpad. We then append the new details and keep a handle to the file. If its an existing word we append to the file. After we are done we loop over each file pointer, read the whole thing into memory, sort it and then save it into the index. Keep in mind you cannot actually keep the file pointer open at all times and just append as there is usually a limit of how many open files exist. Below is the final implementation,``` public function index(array $documents) { if(!is_array($documents)) { return false; }
$indexcache = array(); // So we know if the flush file exists
foreach($documents as $document) { // Clean up the document and create stemmed text for ranking down the line $con = $this->_concordance($this->_cleanDocument($document));
// Save the document and get its ID $id = $this->documentstore->storeDocument(array($document));
foreach($con as $word => $count) {
if(!$this->_inStopList($word) && strlen($word) >= 2) { if(!array_key_exists($word, $indexcache)) { $ind = $this->index->getDocuments($word); $this->_createFlushFile($word, $ind); $indexcache[$word] = $word; }
// Rank the Document
$rank = $this->ranker->rankDocument($word,$document);
$this->_addToFlushFile($word,array($id,$rank,0));
} } }
foreach($indexcache as $word) { $ind = $this->_readFlushFile($word); unlink(INDEXLOCATION.$word.INDEXER_DOCUMENTFILEEXTENTION);
usort($ind, array($this->ranker, ‘rankIndex’)); $this->index->storeDocuments($word,$ind); }
return true; }
The createFlushFile method and addToFlushFile methods are pretty much copies of the methods used in the multifolderindex class. They could presumably be combined at some point, however this is fine for the moment. This takes care of the memory issues with any luck. The results were… promising. It ended up working and using far less memory they before, but because of its constant disk thrashing ended up being more disk bound then CPU. Which is not a good sign when it comes to indexers. This is pretty easy to rectify though, we just buffer the results to flush to disk till they hit some threshold and then dump the lot to disk and start over again.
Fixing the above flaw wouldn't take too much work, but this project has taken enough time as it is. If someone wants to fork it and fix the about feel free.
Anyway I tried the above code, and it worked. The full index took about 24 hours to build (due the issue mentioned before). Searches were reasonably fast and once I increased the amount of documents read from disk quite accurate. Some sample searches like
"source code hosting"
Turned up bitbucket as the main result. Something else like "microsoft windows" shows the official windows site at the top, followed by windows.net and various other microsoft sites.
In fact here are a few queries I tried that I found interesting to play around with, most of which produce fairly decent results.
- digital asset management
- ebay ireland
- antivirus
- celebrity gossip
- weight loss
- microsoft
- microsoft windows
- youtube converter mp3
- domain registration
- news for nerds
- spam free search
- dictionary urban
- online tv free
- photography review
- compare hotel prices
- apple mac
- the white house
- free ebooks for kindle
- computer parts shipping
- os x
- kardashian
- radio social network
- homes for rent
- iron man
- wine making
- apple picking
- php error
- rent a car
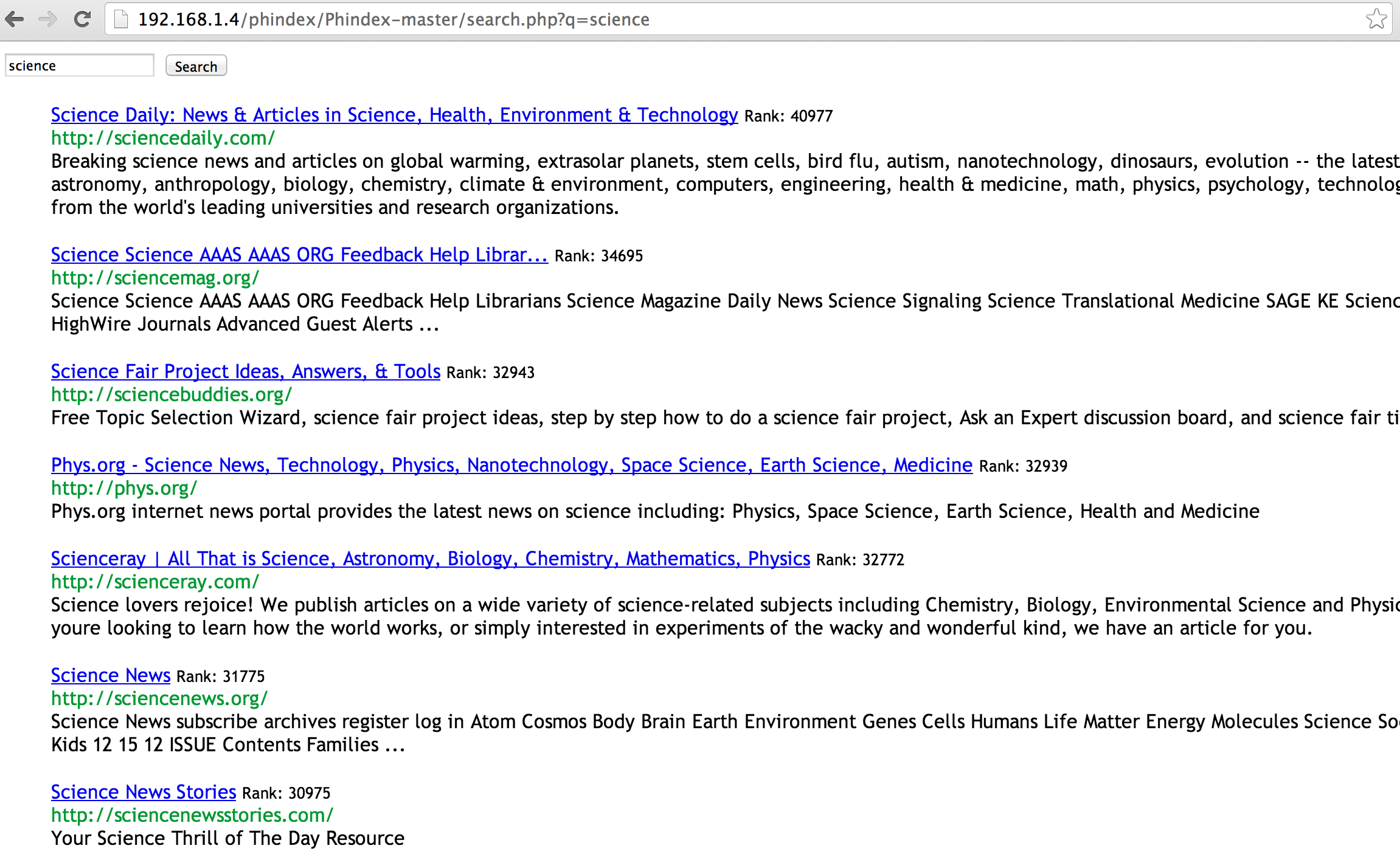
### SAMPLE AND SCREENSHOT
I was going to include a link to a working sample of the site, but have currently run out of time to set it up etc… Setting it up yourself isnt too difficult however, see the instructions below in the downloads section. Here is a screenshot which shows how the whole thing running on my virtual machine.
### CONCLUSION
Well there it is. As promised a full search engine (crawler, indexer, document store, ranker) over a limited set of online documents. The inital goals were to create the following,
1. WebCrawler, indexer and document storage capable of handling 1 million or so documents.
2. Use test driven development to help enforce good design and modular code.
3. Have ability to have multiple strategies for things like the index, documentstore, search etc…
4. Have something I am willing to show off in terms of code.
The first is done, without any real issues. The second I did for the first few steps (before life issues got in the way and started cheating). The third is passed with flying colours. As for the forth, well nobody is ever happy with the code the are releasing but this is good enough for the moment.
If you want to run this yourself, check out the downloads below. Download a copy of the code, do some crawling and index away. Feel free to fork the code and modify to your hearts content. Some things you might want to consider would include, removing the redundant duplicate methods that are hanging around. Things like cleanDocument is repeated all over the place and should live in a single place. Updating the code to flush to disk as mentioned above would be another good step. Modifying it to actually use the indexes third int to store metadata about the word. Fixing the indexing to remove HTML correctly, or perhaps parse out what might be interesting such as bold tags etc…
Thats just a few things off the top of me head that would work.
If you have gotten this far please check out my current project [searchcode][9] which is a source code and documentation search engine, similar to Google Code and Koders. If you want to get in contact me you can reach me on the twitter @boyter or email me at <bboyte01@gmail.com>
All of the downloads mentioned through these articles are here. To get started quickly, download the latest source from github, download the Top 10,000 crawled site data, unpack it to the crawler/documents/ directory and then run add.php This will index the top 10,000 sites allowing you to start searching and playing around with things.
### DOWNLOADS {#downloads}
[Source Code – https://github.com/boyter/Phindex][10] Latest Version
Progress Code 1 – [PHPSearch\_Implementation\_1.zip][11]
Progress Code 2 – [PHPSearch\_Implementation\_2.zip][12]
Progress Code 3 – [PHPSearch\_Implementation\_3.zip][13]
Progress Code 4 – [PHPSearch\_Implementation\_4.zip][14]
Top 10,000 Crawled Sites – [documents.tar.gz][15]
Quantcast top million list – <http://ak.quantcast.com/quantcast-top-million.zip>
[1]: https://leanpub.com/creatingasearchenginefromscratch
[2]: http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-1/"
[3]: http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-2/
[4]: http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-3/
[5]: http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-4/
[6]: http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-5/
[7]: http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-5/#downloads
[9]: http://searchco.de/
[10]: https://github.com/boyter/Phindex
[11]: http://www.boyter.org/wp-content/uploads/2013/01/PHPSearch_Implementation_1.zip
[12]: http://www.boyter.org/wp-content/uploads/2013/01/PHPSearch_Implementation_2.zip
[13]: http://www.boyter.org/wp-content/uploads/2013/01/PHPSearch_Implementation_3.zip
[14]: http://www.boyter.org/wp-content/uploads/2013/01/PHPSearch_Implementation_4.zip
[15]: https://www.dropbox.com/s/vf4uif4yfj8junf/documents.tar.gz?dl=0