This is a follow on piece to my 5 part series about writing a search engine from scratch in PHP which you can read at http://www.boyter.org/2013/01/code-for-a-search-engine-in-php-part-1/
I get a lot of email requests asking how to setup Phindex on a new machine and start indexing the web. Since the article and code was written aimed at someone with a degree of knowledge of PHP this is somewhat understandable. What follows is how to set things up and start crawling and indexing from scratch.
The first thing to do is setup some way of running PHP and serve pages. The easiest way to do this is install Apache and PHP. If you are doing this on Windows or OSX then go and install XAMPP https://www.apachefriends.org/index.html For Linux follow whatever guide applies to your distribution. Be sure to follow the directions correctly and verify that you can create a file with php_info(); inside it which runs in your browser correctly.
For this I am using Ubuntu Linux and all folder paths will reflect this.
With this setup what you need to do next is create a folder where we can place all of the code we are going to work with. I have created a folder called phindex which I have ensured that I can edit and write files inside.
Inside this folder we need to unpack the code from github https://github.com/boyter/Phindex/archive/master.zip
boyter@ubuntu:/var/www/phindex$ unzip master.zip
Archive: master.zip
2824d5fa3e9c04db4a3700e60e8d90c477e2c8c8
creating: Phindex-master/
.......
inflating: Phindex-master/tests/singlefolderindex_test.php
boyter@ubuntu:/var/www/phindex$
At this point everything should be running, however as nothing is indexed you wont get any results if you browse to the search page. To resolve this without running the crawler download the following https://www.dropbox.com/s/vf4uif4yfj8junf/documents.tar.gz?dl=0 and unpack it to the crawler directory.
boyter@ubuntu:/var/www/phindex/Phindex-master/crawler$ tar zxvf documents10000.tar.gz
...
...
boyter@ubuntu:/var/www/phindex/Phindex-master/crawler$ ls
crawler.php documents documents10000.tar.gz parse_quantcast.php
boyter@ubuntu:/var/www/phindex/Phindex-master/crawler$
The next step is to create two folders. The first is called “document” and the second “index”. These are where the processed documents will be stored and where the index will be stored. Once these are created we can run the indexer. The folders need to be created in the root folder like so.
boyter@ubuntu:/var/www/phindex/Phindex-master$ ls
add.php crawler index README.md tests
classes documents interfaces search.php
boyter@ubuntu:/var/www/phindex/Phindex-master$
With that done, lets run the indexer. If you cannot run php from the command line, just browse to the php file using your browser and the index will be built.
boyter@ubuntu:/var/www/phindex/Phindex-master/$ php add.php
INDEXING 1
INDEXING 2
.....
INDEXING 10717
INDEXING 10718
Starting Index
boyter@ubuntu:/var/www/phindex/Phindex-master/$
This step is going to take a while depending on how fast the computer you are using is. Whats happening is that each of the crawled documents is processed, saved to the document store, and then finally each of the documents is indexed.
At this point everything is good. You should be able to perform a search by going to the like so,
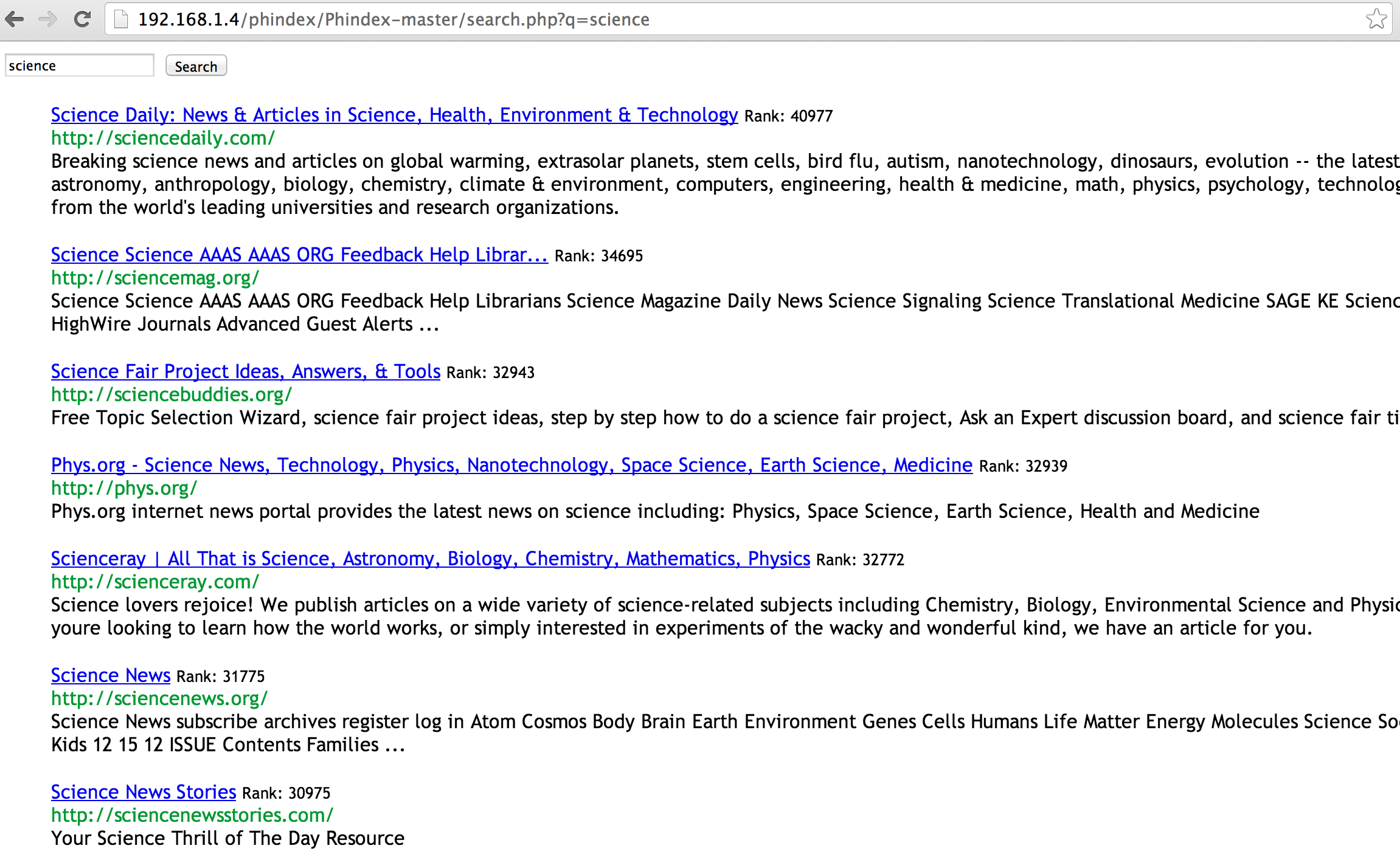
At this point everything is working. I would suggest at this point you start looking at the code under the hood to see how it all works together. Start with add.php which gives a reasonable idea how to look at the crawled documents and how to index them. Then look at search.php to get an idea on how to use the created index. I will be expanding on this guide over time based on feedback but there should be enough here at this point for you to get started.