27th July 2016 at about 9:30pm my local time (GMT +10) I updated the A records for searchcode’s nameservers to point at a new stack that has been several months in the making. As with most posts of this sort of nature a quick recap of where things were and where they are now.
The previous searchcode stack consisted of two dedicated servers hosted by Hetzner. I have previously discussed this about two years ago when discussing searchcode next. The first server was a reasonably powerful machine running pretty much all of code required to deliver searchcode.com itself with the exception of the actual index. searchcode is a Django application and was using nginx to serve results directly out of memcached where possible to avoid consuming a running Gunicorn process. The move to have another server for the index came pretty quickly after searchcode was released as it was just not performant enough with everything on a single box which was the situation for a short time.
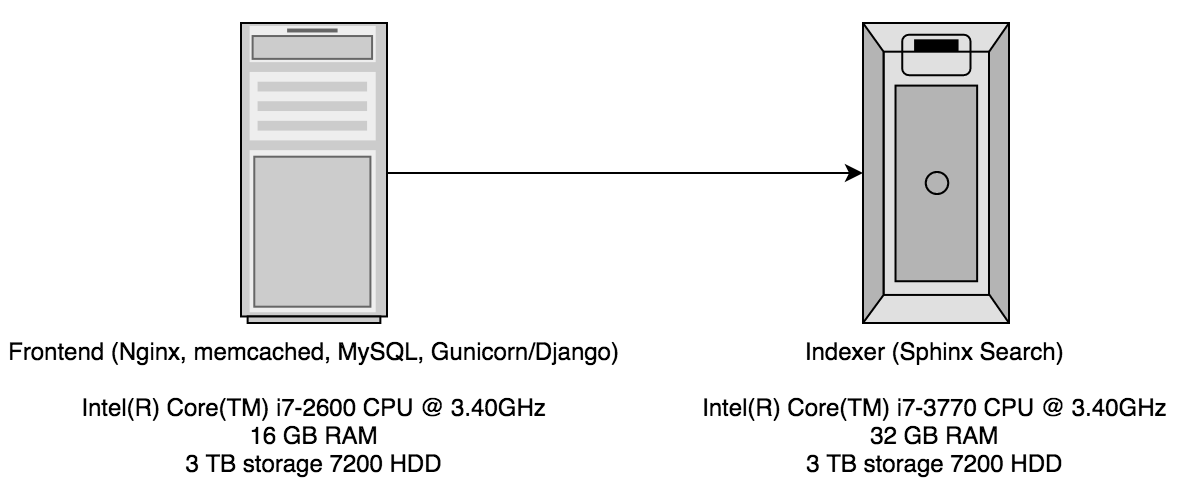
This structure worked well for the last 2 years or so but I had noticed that the load average on the frontend was starting to average out at about 3.0+ and would quite often rise to 7.0+ Considering the machine had only 4 real CPU cores this was an issue. Interestingly it also caused the number of requests that searchcode could respond to to max out. In addition the MySQL database had some corruption somewhere in the middle which made to app increasingly unstable. The application was going down where nothing short of a reboot would save it at least once a month. Finally I had grown as a developer over the last two years and it was time to move to something more stable and better performing.
The first thing in this modern cloud world was start looking at moving to something like AWS or DigitalOcean. I firstly created a simple spreadsheet with what I was looking to move towards along with expected costs. In short I wanted to break searchcode apart so that it consisted of the following parts,
Frontend server. Would provide SSL termination to Varnish and reverse proxy back to application servers. Requires, either a lot of RAM or fast disk. If RAM is low but disk is fast can use Varnish with disk cache.
Backend server. Would run the application itself. Scales horizontally. Requires a fast CPU to process the code results.
Indexer server. Would host the Sphinx indexer. Scales horizontally. Requires a fast CPU, reasonable amounts of RAM and about 25 GB of amount of disk space per CPU core, preferably SSD.
Database server. Would host the MySQL database. Does not scale horizontally. Requires lots of RAM (more than 4 GB) and 2 TB of disk space.
With these requirements in mind. I started shopping around.
AWS was ruled out almost immediately due to the cost. This was in spite of the fact that I have a great deal of experience dealing with the AWS API’s. As a rule I run searchcode.com as lean as possible and AWS while brilliant ended up costing more than I would have liked.
I then started looking at DigitalOcean. I have always been a fan of how fast they spin instances up, the simple API and their prices. They also have excellent support and are pretty lenient when it comes to how much CPU and DiskIO you consume. When I started looking however they had not launched Block Storage, which meant I needed the $640 a month plan for the database which was even more expensive then AWS. Later they did release block storage, but the resulting price was still rather high. I still use DigitalOcean for spinning up test stacks.
I also looked at Vultr. It’s pretty safe to say they are a DigitalOcean clone but with more data centers, competitive prices and much worse customer support. They do have one intriguing server option however not mentioned on their public website, which is a storage server. It’s a server backed by a regular spinning rust style disk, but as such is far cheaper than anything offered by any other company. A database server with 1 TB of storage, 4 GB RAM and 2 CPU’s (the largest storage instance they have) is only $40 a month.
A believer in infrastructure as code I was very keen to move to one of the cloud servers and picked Vultr based on the storage instance and cost. I started importing the searchcode database into the storage instance. However about 3/4 the way through I received an email from Vultr support saying that I was exceeding the DiskIO of the storage instance using a sustained 125 IOPS. Fair enough, and I would have been willing to throttle it back if I could gain some assurance about the terms of service. Sadly Vultr lived up to their reputation of having poor support and I am yet to hear back. I terminated the instance and started looking again. They do offer dedicated instances and the prices are actually not too bad, but did not have enough disk space for my needs. I still use them for spinning up test stacks as they have a Sydney data centre which for me has lower network latency and offsets the slower creation time.
I realised that the only real option for something like searchcode (which is fully bootstrapped) is that I need as much power as possible and the lowest price. I also don’t mind getting my hands dirty and can deal without the support. Lastly I need to be able to abuse the machine as I see fit and the only way to do that is go dedicated.
Thankfully Hetzer has a very nice server auction house. You can browse through and pick up used servers for a considerable discount over a new order. In addition you don’t have to pay the setup fee. To avoid the database corruption issue I experienced previously I went shopping for a ECC RAM server for the database and quickly found a tidy machine with 32 GB RAM and enough disk space. For the frontend I just picked up the cheapest 32 GB machine I could find which interestingly was similar to my previous frontend machine but with 32 GB of RAM. Lastly I went looking for something to server as the backend and the indexer. I quickly realized that I could combine both the machines into one and save a few dollars. With this saving I was able to overlook the initial setup fee and went for two machines with 32 GB of RAM and 500 GB SSD’s. Since Hetzner cannot spin servers up and down like a cloud provider I hard-coded the details into my fab file for building the stack but otherwise everything deploys as though I was using a cloud provider. Only it costs considerably less and should be much much faster.
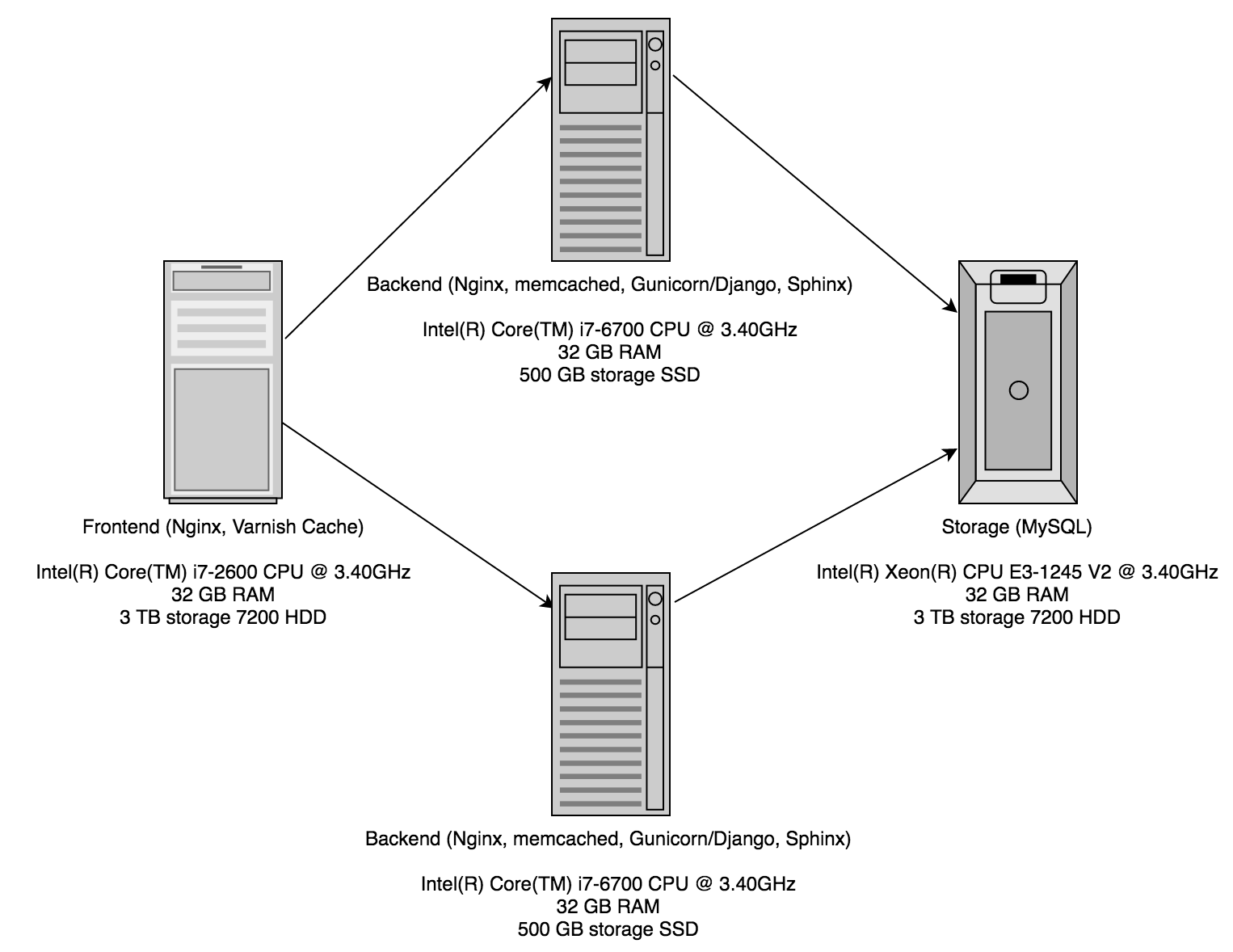
The results?
Well as mentioned the previous instances were sitting around a load average of 3.0+ most of the time. The new backend/indexer boxes are sitting at a load average of 0.1+ which is a massive improvement. The database and frontend are similarly loaded. The DNS at this point is still flipping over for some so its not serving all results yet but I cannot imagine the load rising beyond 1.0+ for everything.
With the hardware decisions discussed lets dive into the software starting with the data storage. MySQL has always been my database of choice simply because I am more familiar with it than any other database. I had previously toyed with migrating to Postgresql but decided against it simply because there are other things I should focus my time on that actually provide real value. As such I have stuck with that for the latest searchcode version however one change I did make was to upgrade to 5.7 so I can leverage the native JSON data type. Otherwise the only change was to modify the MySQL config to take advantage of the power of the box as per best practices.
The backend machines have Nginx set to listen to incoming connections from the frontend. They pass requests back to Gunicorn/Django which performs the appropriate action. Where possible the result using Django/Memcached is served directly, if not a request to Sphinx may be made for search results followed by a lookup to the database, or a direct request to the database. Gunicorn is configured to have four worker processes per box. Sphinx is configured using a distributed index with 4 agents running on each box and one box as the master. Memcached is currently configured with 8 GB of RAM for each backend instance but is not pooled together.
The frontend machine is configured using Varnish with 24 GB of the RAM allocated to cache. The remaining 8 GB is deliberately left over for use by OS caching and Nginx. Nginx is the frontend to the whole system providing SSL termination and proxying back to Varnish. I did briefly consider using HAProxy for this role, but since I was already familiar with Nginx and at the scale searchcode currently operates at Nginx was a better choice. If in time there is much greater load moving to HAProxy is something that will be considered.
Whats next? Well the future of searchcode.com at this point is to leverage the new machines to increase the size of the index and make it refresh the code more quickly. I have a few plans on how to do so and will release details in the next update. If you have read this far you are a beast! Thanks for the support and feel free to email with any further questions.