
Developer? Need to know how to use Elasticsearch? Want to know how to get working with it quickly? This is the book for you! Buy now using Leanpub
In elasticsearch mappings define type and values in documents. You use them to specify that fields within your document should be treated as numbers, dates, geo-locations and whatever other types elasticsearch supports. You can also define the stemming algorithm used and other useful index fields.
You have to define a mapping if you want to provide functionality such as aggregations or facets. You cannot add a mapping after indexing any document. To add one afterwards requires dropping the index and re-indexing the content.
You define a mapping by putting to the index/type inside elasticsearch before then adding a document. Consider for example this document defining Keanu Reeves.
{
"fact": "Originally intended on becoming an Olympic hockey player for Canada.",
"type": "Actor",
"person": {
"name": "Keanu Reeves",
"DOB": "1964-09-02",
"Citizenship": "Canadian"
}
}With the below definition the person.DOB field will be treated as a date in the format yyyy-MM-dd and will ignore malformed dates. Malformed dates being dates which have a non matching format or are empty. It will also treat the type field of the document as a single keyword allowing us to perform aggregations and facets on this field.
PUT: <http://localhost:9200/film/>
TYPE: application/json
{
"mappings": {
"actor": {
"properties": {
"person.DOB": {
"type": "date",
"format": "yyyy-MM-dd",
"ignore_malformed": true
},
"type": {
"type": "keyword"
}
}
}
}
}To set the mapping you need to PUT the above to an index, such as http://localhost:9200/film/ which would create the new type of actor with the mappings as specified. The result of this would look similar to the below,
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "film"
}With this done you can then put the actor document to http://localhost:9200/film/actor where it would be indexed against the mapping.
There are ways to add dynamic mappings where elasticsearch will guess the type, but generally I found this more problematic then its worth. Explicit is always better then implicit when it comes to code in my opinion.
With the above done you can now perform facet/aggregation queries against documents of type actor in the film index.
Facets / Aggregations
One of the things you likely want from your search are facets. These are the aggregation roll-ups you commonly see on the left side of your search results allowing you in the example of Ebay to filter down to new or used products.
Sticking with our example of Keanu you can see that in the below mock-up that we want to be able to filter on the type field of our document so we can narrow down to actors, directors, producers or whatever other types we have in our index.
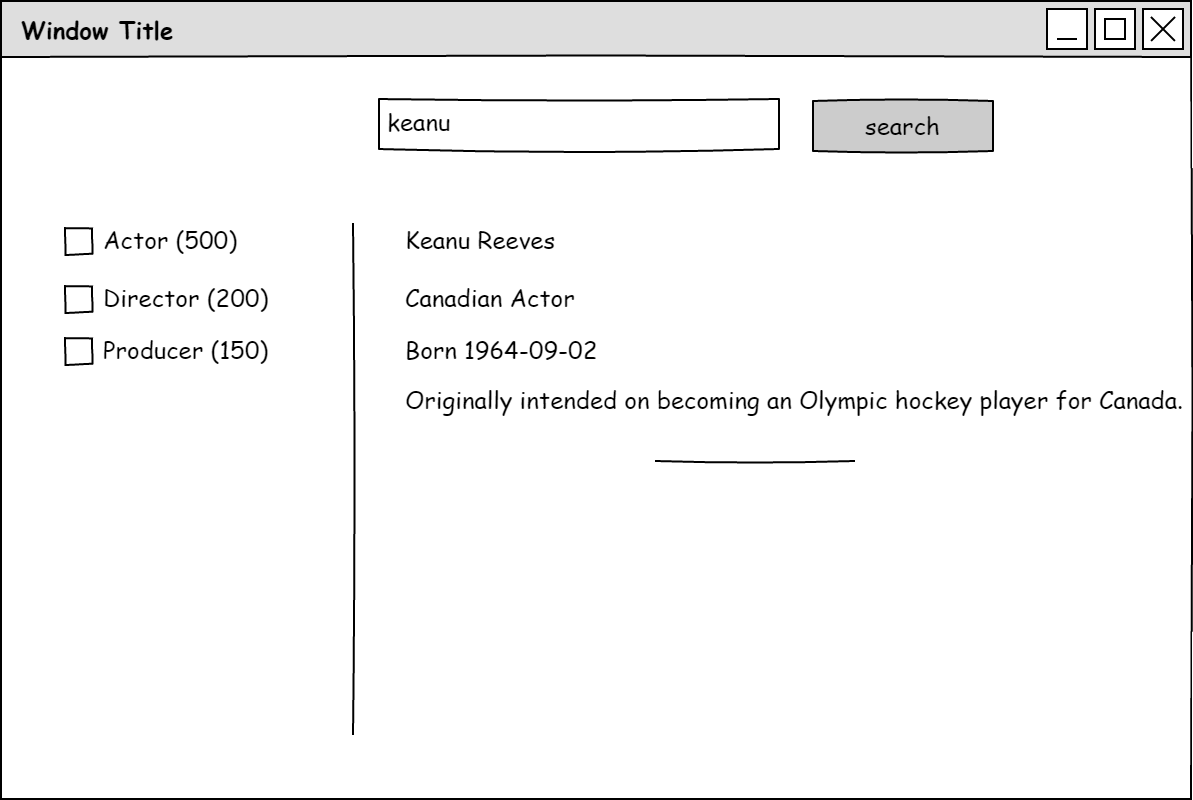
Facets are the result of setting the keyword type in the mapping. Once you have set the mapping then added the document you can then request facets to be produced for that field.
To generate facts for a search you want to run a search with some aggregations set.
POST: <http://localhost:9200/film/actor/_search>
TYPE: application/json
{
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "keanu",
"default_operator": "AND",
"fields": [
"person.name",
"fact",
"person.citizenship",
"_everything"
]
}
}
]
}
},
"aggregations": {
"type": {
"terms": {
"field": "type",
"min_doc_count": 0
}
}
}
}When run against an index with the mapping setup you will get back in your response the following,
"aggregations": {
"type": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Actor",
"doc_count": 1
}
]
}
}Which is a sum of each of the unique keys based on the field you specified. You can have multiple aggregation types if you have multiple facets, with each having the key of the name you set in your aggregation request.
Once you have the facet you can then filter results down to just those containing it. You can do this like the below example that will filter down to a any document where the type is set to “Actor”.
POST: <http://localhost:9200/film/actor/_search>
TYPE: application/json
{
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "keanu",
"default_operator": "AND",
"fields": [
"person.name",
"fact",
"person.citizenship",
"_everything"
]
}
}
],
"filter": {
"bool": {
"must": [
{
"term": {
"type": "Actor"
}
}
]
}
}
}
},
"aggregations": {
"type": {
"terms": {
"field": "type",
"min_doc_count": 0
}
}
}
}The result of the above is to filter to documents of type actor inside the film index where their type is set to Actor. You can of course add additional filters like this, so say you wanted to filter to single years this would work, although date/time filters would be a better solution to this problem.