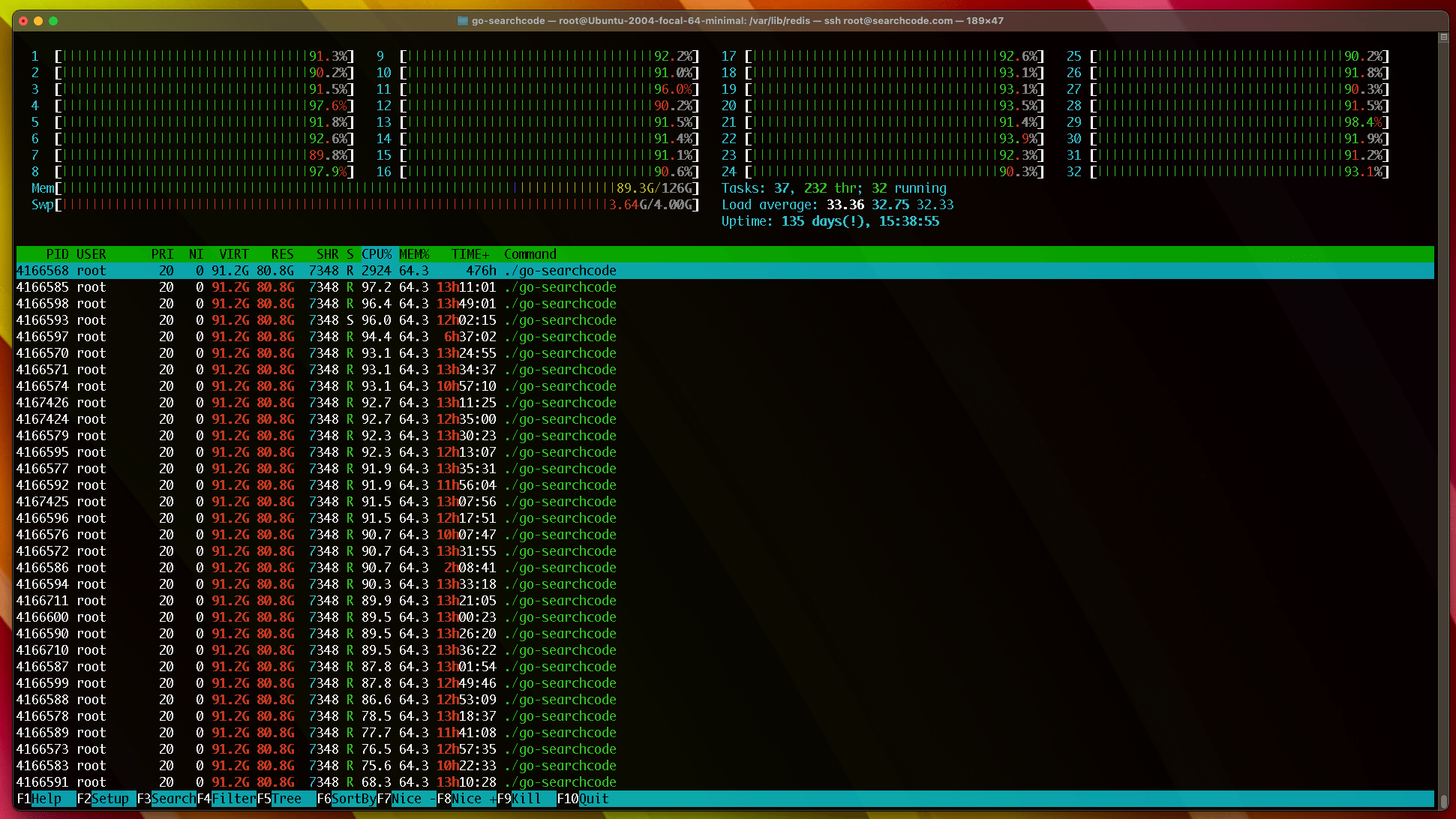
Another progress update on https://searchcode.com where I was trying to reduce the time it takes to index source code. Since the this was a real world example of profiling code trying to reduce its cost I thought I would document how it went.
The first step is to add code allowing the collection of a profile.
I don’t do this often enough in searchcode to have a want to enable/disable this so I just comment/uncomment this when needed. Note that I have this set to stop profiling 30 seconds after it starts, which is more than enough for me to identify CPU pressure as the index process is the first thing to start.
f, _:= os.Create("profile.pprof")
_ = pprof.StartCPUProfile(f)
go func() {
time.Sleep(30 * time.Second)
pprof.StopCPUProfile()
}()With that done, I start searchcode, wait 30 seconds for it to index and then can look at the profile.
go tool pprof -http=localhost:8090 profile.pprof
We get the following flame graph.
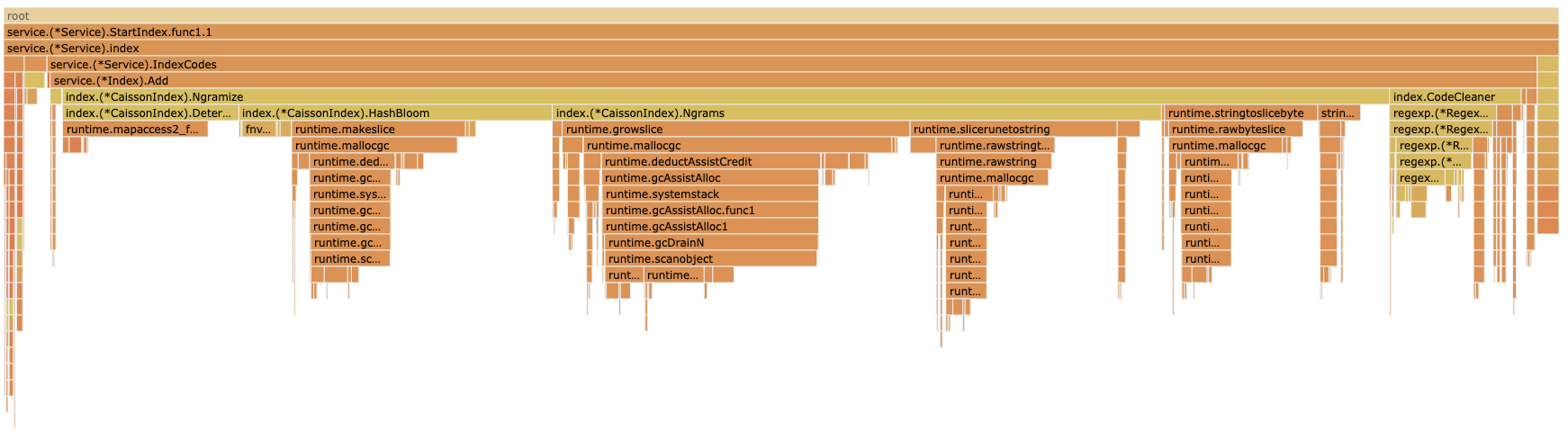
The bit I am most interested in is index.(*CaissonIndex).Ngrams because I know most of the other methods I have looked at in detail previously.
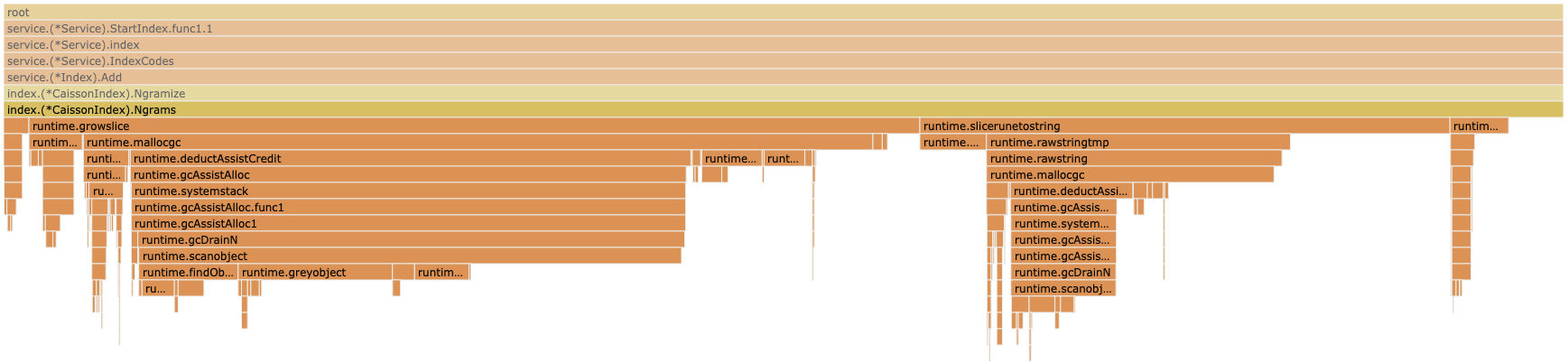
The easiest thing to optimise there looks like the runtime.growslice operation. This appears when you are appending to a slice. Looking at the code shows that is indeed what happens.
func (ci *CaissonIndex) Ngrams(text string, size int) []string {
var runes = []rune(text)
ngrams := []string{}
for i := 0; i < len(runes); i++ {
if i+size < len(runes)+1 {
ngram := runes[i : i+size]
ngrams = append(ngrams, string(ngram)) // <-- PROBLEM HERE
}
}
return ngrams
}I wrote this to be generic at the time in case I ever wanted to change the length of the ngrams, but in reality I only ever use trigrams. Knowing this, we can know how many ngrams we expect, and so rewrite the method to remove the append and instead allocate the slice once, then assign values in it. I could do that for the other method too, but being more explicit is a virtue.
func (ci *CaissonIndex) Trigrams(text string) []string {
var runes = []rune(text)
if len(runes) <= 2 {
return []string{}
}
ngrams := make([]string, len(runes)-2)
for i := 0; i < len(runes); i++ {
if i+3 < len(runes)+1 {
ngram := runes[i : i+3]
ngrams[i] = string(ngram)
}
}
return ngrams
}Is this the most optimal way to tokenize ngrams? I honestly have no idea. I thought about looking at how NTLK does this in Python but have yet to do so. I suspect whatever its doing is fairly optimal. Consider yourself nerd sniped if you are reading this. I would love to have a faster way, as this is by far the slowest part of searchcode’s index process. I have some ideas on how to speed this up… but nothing concrete yet.
Anyway after swapping over to this new version time to rerun the index process and see what happens.
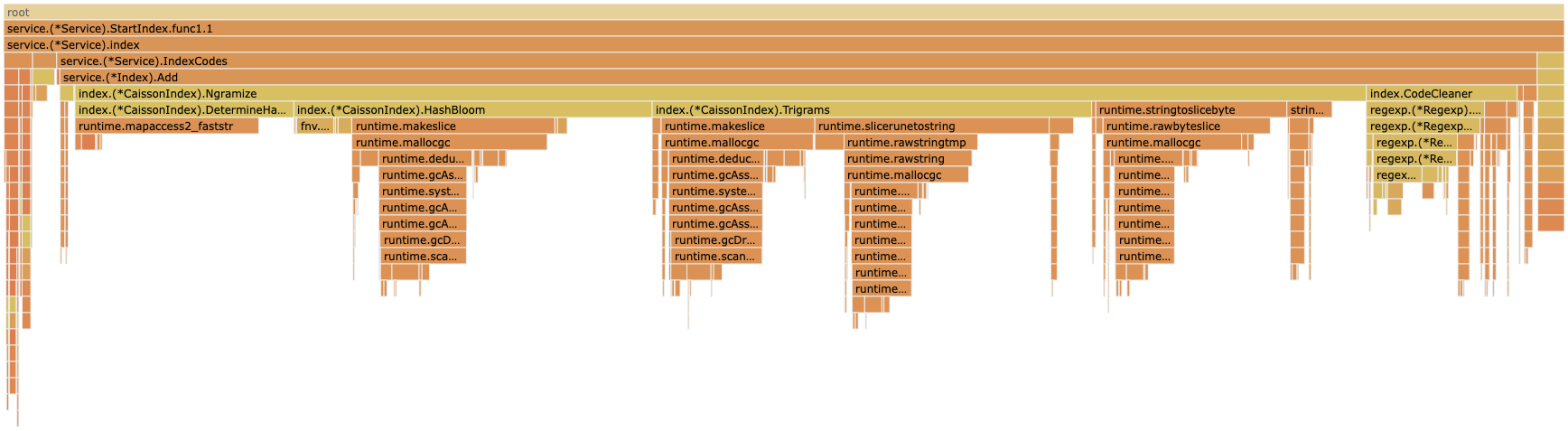
Zooming in
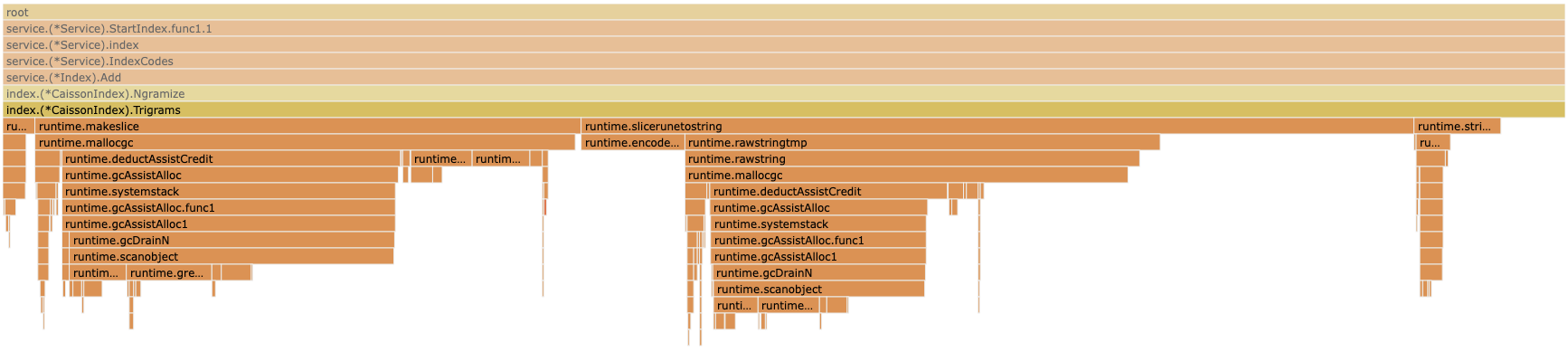
We have eliminated the grow runtime.growslice. A win! Also one that took less than 20 mins to diagnose.
The result? When reindexing searchcode takes about 10% less time. When you consider a full reindex takes the better part of 24 hours thats a huge win. Especially when while its happening your CPU looks like the below.