With the rise of AI LLM technology, I naturally wanted to learn more about using it. Both from a what can it do but also where can I use it in various tasks. Since I am also investing more time in searchcode.com these days I wanted to find a way I could use these tools to improve it.
One of the easiest things I could think of was by creating summaries of each file. This could then be used in both the HTML title, description and on the page assisting users with what they are looking at. I find these fairly useful at times, and I quite often ask LLM’s what something does when working with unfamiliar languages or codebases.
The idea was to run every code fragment searchcode knows about through a LLM and get a snippet returned that I could embed on the page. An example of how this appears is below, with the snippet displayed in the right column. You can view it here https://searchcode.com/file/51394/trunk_go/nonce/nonce.go/ if you want to see a live view.
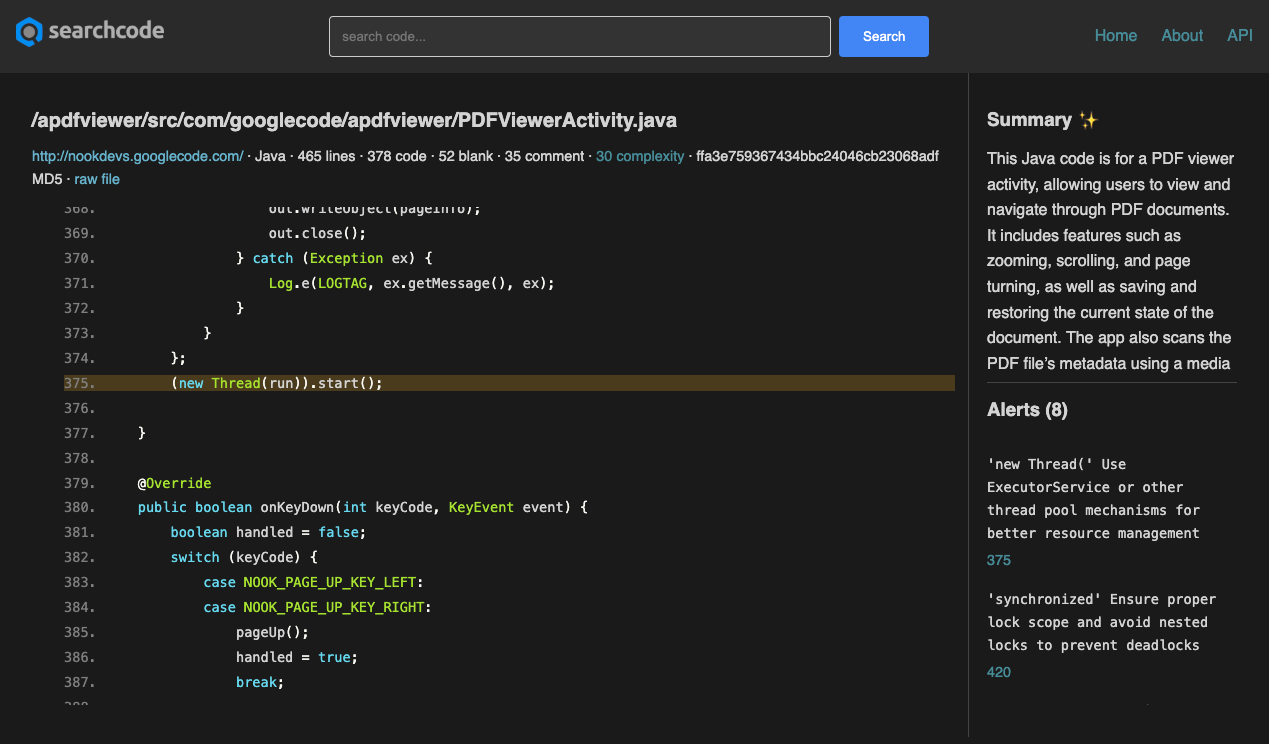
The next problem was which model to use? Keeping up with the best model is a full time job these days, with an endless cycle of the main players leapfrogging each other. My requirements were fairly simple. I wanted to be able to throw some code at it, and get back a reasonable summary.
I tried a variety of models and as it turns out for this task any modern LLM worked surprisingly well.
Where things started to get spicy was when it came to costs. As a test I tried running 10,000 requests though the cheapest model that worked for me at the time which was a version of Gemini Flash from Google. The result for this limited subset of data was a bill of $10. Not excessive, but considering I want to run over well over 100 million results through this it was going to become prohibitively expensive.
The plan as such rapidly became how to run this locally using whatever hardware I have lying around. Some time ago I bought a Mac Mini M2 as a home “server”. So I started looking into what models it could run. This is where the main cost aside from electricity cost which I will cover at the end of this post.
The easiest option to run a LLM locally in this case is Ollama which in addition to being stupidly easy to setup has a nice library for Go github.com/xyproto/ollamaclient which made connecting everything together very easy.
func Analyse(prompt string) (string, error) {
oc := ollamaclient.New("llama3.2")
oc.Verbose = false
return oc.GetOutput(prompt)
}
I did try some of the other models provided by Ollama including codellama, but found that llama3.2 worked best for my needs producing the best results without taking too long to generate.
The prompt to for the above is fairly simple, although I had to be very explicit about not asking for improvements or suggestions.Every model I tried without fail would take whatever code was given and start to refactor it for me, which probably fits in with their default instructions to be helpful.
>>CODE ESCAPED AND INSERTED HERE<<
Explain the above LANGUAGE_NAME code output in 80 words or less. Return markdown but without any headers or lists.
Just tell me what it does. Keep the answer short. GIVE NO improvements or suggestions.
For storing the results, I opted to keep the analysis away from the main code table. In fact it lives in its own SQLite database which I update independently. The table structure follows, with the main takeaway being to store both the source of the content and the model used. I also keep the size of the content, which in this case is kept at approximately 80 words. These columns are important if I ever decide to swap out the models or change the prompt output size and should allow me to evaluate different models.
sqlite> PRAGMA table_info(code_analysis);
0|id|INTEGER|0||1
1|code_id|INTEGER|1||0
2|source|TEXT|1||0
3|model|TEXT|1||0
4|content|TEXT|1||0
5|size|INTEGER|1||0
sqlite> select * from code_analysis limit 1;
1|3|oolama|llama3.2|This Python code is part of a window manager for X11, handling various events such as mouse and keyboard input, window movements, focus changes, and exposure notifications. It updates the window's state and dispatches events to notify other parts of the system about these changes, allowing them to react accordingly.|80
A screenshot of me connecting to my “server” doing its things. As you can see I have it doing a lot of background tasks, with this generation being probably the most power intensive one, which you can observe from the 100% GPU usage in the top bar.
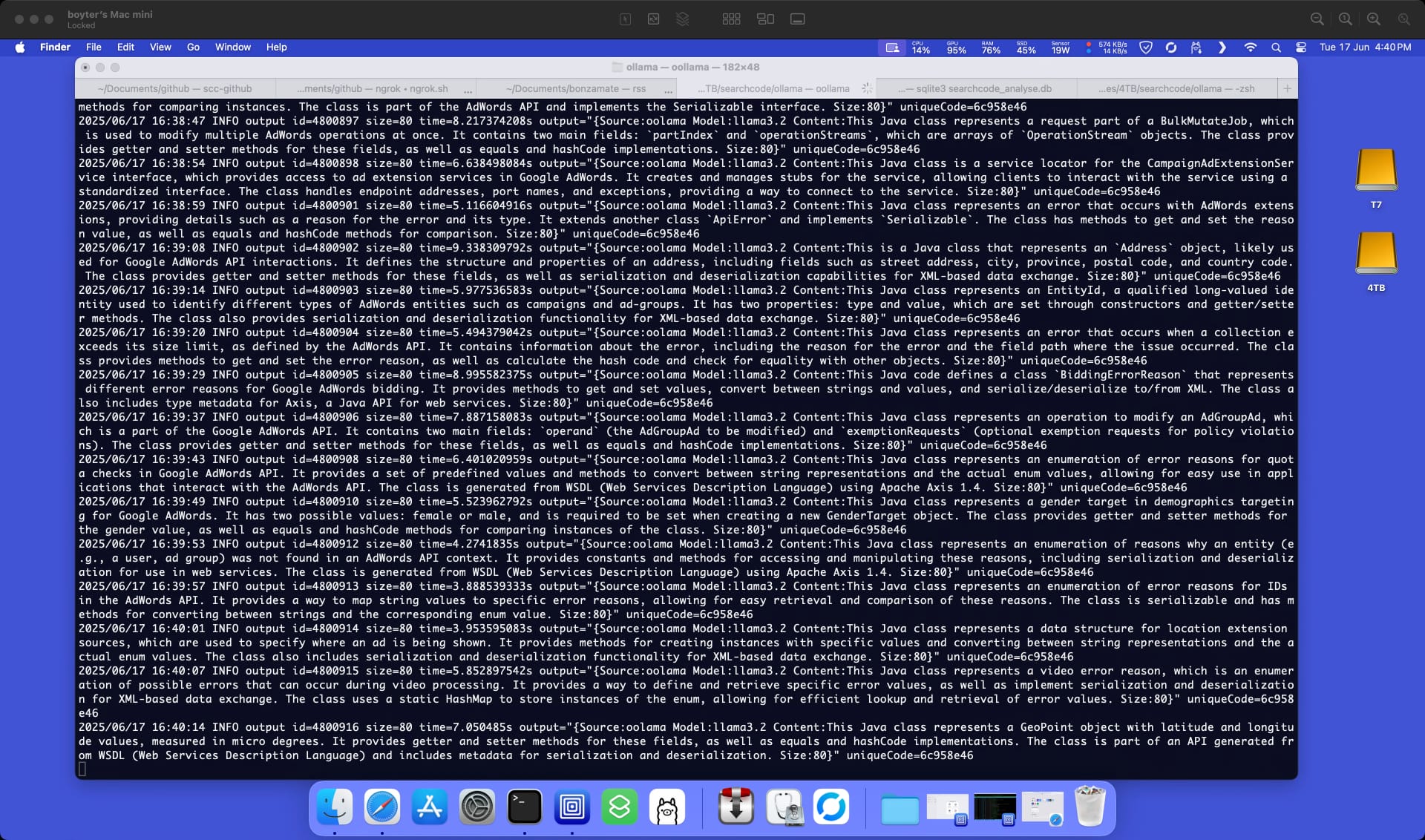
Generation of snippets takes from 1-9 seconds depending on what is being processed. The average appears to be in the region of 3-4 seconds which is perfectly acceptable for my use case.
Every now and then I sync the database back up to searchcode.com replacing the existing database and serving the results up. While writing this post I ran the sync and while there did a quick count on the database to see how many results exist.
sqlite> select count(*) from code_analysis;
3231595
So there it is. A home solution to producing LLM outputs, while saving me literally hundreds of thousands of dollars. You can replicate such a setup for less than $1000 even using Aussie Dollarydoos with the cheapest least expensive Mac Mini costing just $999. Throw in a decent UPS and you have a pretty decent solution to this sort of problem.
Of course the last thing is the question of power costs.
I am counting the power for this to be more or less free. While power costs in Australia are far from being cheap (around 31 c/kWh), I do have solar and so can run this effectively for free during days where I would otherwise be exporting power. The Mac is also very power efficient pulling about 25w from the wall while performing this task. You may need to adjust accordingly if you do such a thing on a 5090 or some other GPU… albeit factoring in how much faster it would generate the results.