Unicode support in my experience seems to be one of those hand wavy things where most people respond to the question of “Do you support unicode?” with
Yeah we support emojis, so yes we support unicode! 😃😭😈
Which is partially correct… It’s certainly a good start. However unicode is more than emojis.
So lets take a step back. What is unicode? It’s actually easy to explain, here it is taken from the wiki page “A standard for representing the worlds text”. That means it includes all the languages in the world, such as chinese characters, japanese writing systems, arabic and even nordic runes. As such you get all sorts of interesting things in the standard such as characters that display as white space but actually are not because they represent a nordic rune carved on the side of the stone not visible from the front.
Being able to save these characters into your system as mentioned a very good start. Emoji’s tending to be the yard-stick used to test a unicode support claim, because who doesn’t love sprinkling them through everyday communication.
However what true unicode support actually means, if you perform string operations on unicode characters are you able to process them correctly. Note I am not covering encoding here, but this classic Joel on Software post covers it well enough. Your programming language of choice might have functions to help you with this, or have they enabled on your string functions already. But lets consider what this entails.
The first thing is that your language needs to know how to split and count strings based on the number of characters and not the bytes that represent them. If you count the number of characters in Ⱥ using the string function inside your language of choice, and get back the answer 1 then fantastic your language natively supports unicode. If you get back 2 then you are actually getting the count of the bytes it takes to represent the character. However there is more to unicode then knowing how many characters string holds. That thing being case folding rules.
Case folding rules I hear you ask? 🙏
In modern English generally a single upper-case character has a 1 to 1 mapping to a lower-case character. A-a B-b C-c etc… However once you move to older English and international languages this is no longer true. For old English once you include unicode characters all of a sudden you have to deal with things like ſ.
According wikipedia the character ſ is a long s. Which means if you want to support unicode you need to ensure that if someone does a case insensitive comparison then the following examples are all string equivalent.
ſecret == secret == Secret
The above is just a simple example… consider the following (not all permutations included),
ſatisfaction == satisfaction == ſatiſfaction == Satiſfaction == SatiSfaction === ſatiSfaction
As you can see there is a loss of information in some of the above too. If you go from ſ to S you have lost some information and there is no way to go back to what you started with. So by changing case you potentially don’t actually know which character to use. The classic example for this in unicode is the French word cote. Because cote, coté, côte and côté are all different words with the same upper-case representation COTE. Also, an astute reader pointed out that in French Canadian it actually does upper-case with accents, adding some more depth to unicode operations localization which is something I have never investigated so won’t discuss in depth.
The above is something to keep in mind from design to implementation. Because your design might require that you lower-case/upper-case/title-case something to look better, and this might be losing information while doing so.
Actually it can be more complex than the above. The above is dealing with simple case folding rules, where a single character maps to a single character (although it could map to be multiple single characters). Full case folding rules mean that one character can actually map to multiple.
Let’s look at the German character ß. Which under full-case folding rules actually has two mappings, one to a single character and one to two characters.
groß -> GROẞ | GROSS
When you upper-case groß you can get either GROẞ or GROSS. Depending on how old the person you are working with one might be considered correct or according to Council for German Orthography both can be correct.
Another good example to consider is the character Æ. Mostly because I have some personal experience with it.
Under simple case folding rules the lower of Æ is ǣ. However with full case folding rules this also matches ae. Which one is correct? Well that depends on who you ask, but consider the following on page search done in Chrome and Firefox.
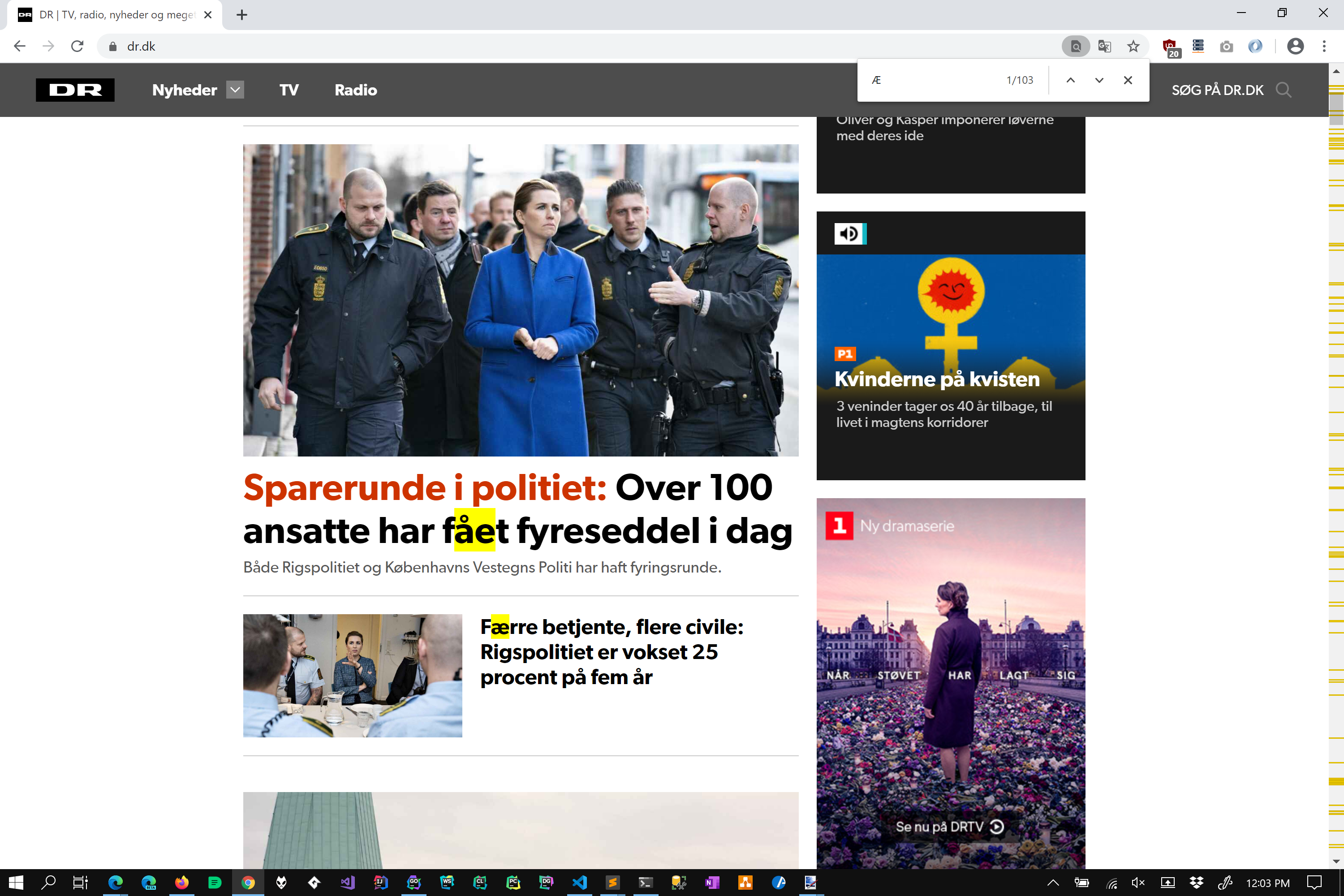
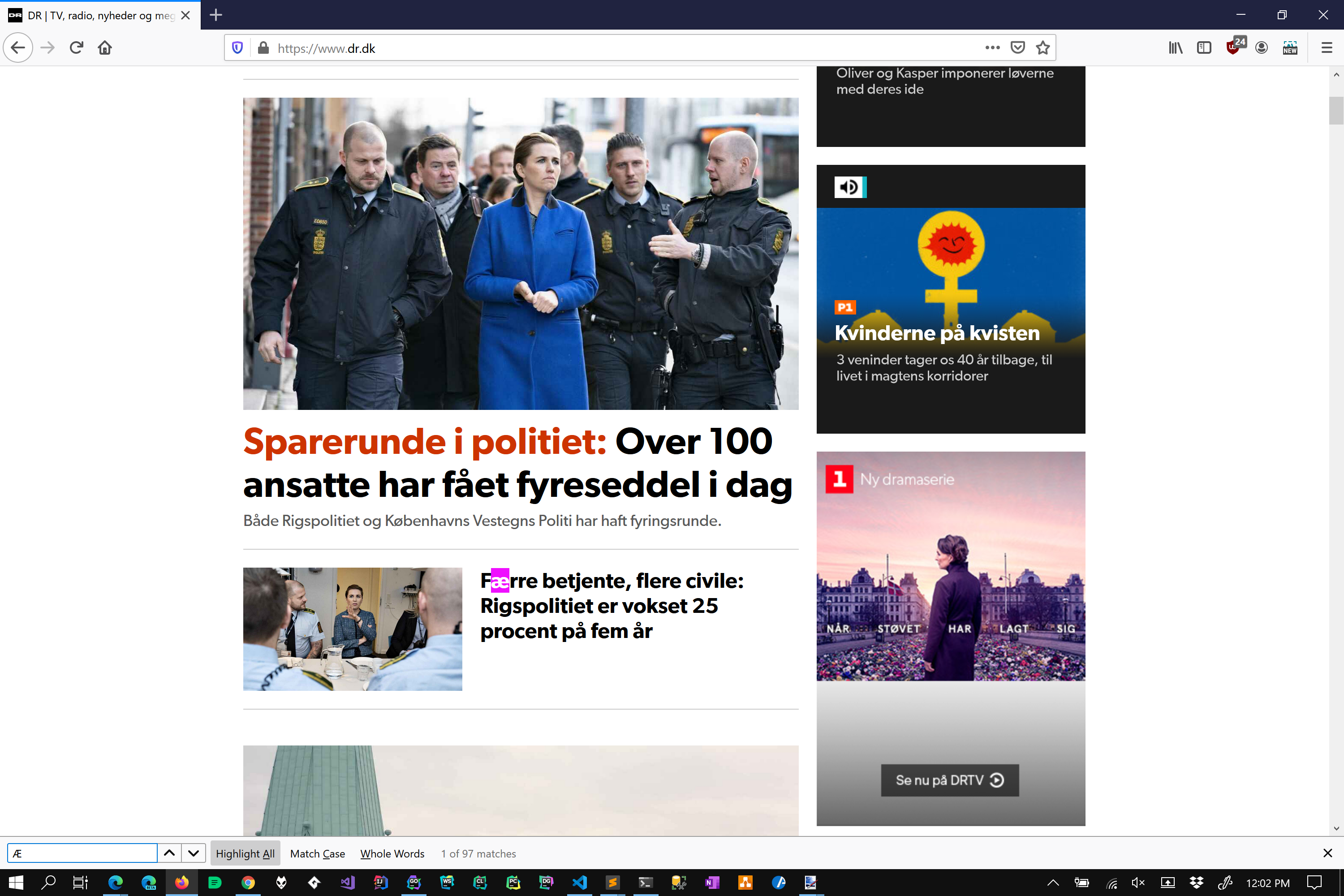
Chome (Edge does the same thing) follows full case folding rules (which also maps Æ to accented ae variants!), where-as Firefox follows simple case folding rules. Which one is correct? I asked a work colleague from Denmark, and he actually liked both depending on what he was searching for and the context of the page. So there is no clear answer as to which one you should implement, BOTH types can be considered correct.
That’s one of the issue’s with stating “unicode support” in any software product. Your implementation probably isn’t wrong, but it might not be what the user expects.
So dealing with case-folding is clearly a lot of work. How about we just work with bytes? The string is just bytes under the hood after all… 🤔 This incidentally was the response I got from a resident C programmer. Lets forget case folding and just worry about the “normal case”. If we lower-case/upper-case everything and work like that everything be fine yes?
Consider trying to make a search engine 🔍. After finding some relevant results you probably want to highlight matches inside the result. That is the user searches for something and expects you to highlight that term in the results page. Lets consider the following search string,
java
and the text we have found and now what to highlight.
the regex can work with Ⱥ. Java by contrast will
Clearly we want to match java. So you lower-case both the search text and the content. Find the offset position. Then against the original content you markup. And you get something like
the regex can work with Ⱥ. Java by contrast will
Wait what happened there? We should be bolding Java, not just ava.
The culprit as you probably have guessed is Ⱥ. However why? Well it turns out that Ⱥ takes 2 bytes to represent. However its lower-case variant takes 3 bytes. So when you calculate the index unless you deal with the original string you are going to have off by 1 errors for each character that does this.
At which point you go, fine i’ll just search for all case variants of Java and use that to work things out, and then realise adding case folding is a small addition to what you just wrote and working with just bytes to save time was a red-herring.
It also means that you cannot explicitly assume that the lower/upper-case representations of any two strings are not the same just by checking the bytes.
For those curious here is a Go program which illustrates the difference in byte sizes for a character to prove the point.
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println("Ⱥ", strings.ToLower("Ⱥ"), len("Ⱥ"), len(strings.ToLower("Ⱥ")))
}Keep in mind this is just scratching the surface of the edge cases in unicode. I’m sure there are heap of additional cases I have not yet run into nor covered (I was only trying to solve a single small problem) but this should at least give an idea as to the sort of problems you need to consider.
There are also security implications to consider when working with unicode such at the ones rasied here https://eng.getwisdom.io/hacking-github-with-unicode-dotless-i/ where blindly lower casing email addresses results in a security issue.
One last thing to consider is the performance cost of supporting unicode, which unless you pay special attention can be non trivial. Probably best illustrated by the ripgrep introduction blog https://blog.burntsushi.net/ripgrep/#linux_unicode_word and specifically the unicode aware test where some of the tools get a non trivial order of magnitude slow down cost by supporting it.
So… key take-aways.
- You cannot explicitly assume that the lower/upper-case representations of any two strings are or are not the same by checking the underlying bytes
- Case folding can be done in one or two ways, simple and full
- Sometimes people like both versions
- Oh and you need to consider localization
- As well as normalization where a following diacritical mark can make what appears to be a single character multiple
- Even big players implement different versions in the same tools including Microsoft, Google and Mozilla
- There are also potential security issues that can come from not getting things right
- There can be non trivial performance costs to support unicode
So what to do? Well the first is obviously use well supported libraries that solve this problem for you. However be aware of the limitations they have. Know what case folding it supports for instance. I’d also suggest not claiming to have unicode support unless you are very explicit with what you support, or know in advance what the user expects. I would be inclined to ask “Can you develop that point please?” when faced with this question.
Saying “We support it this way” is acceptable in my books, but might come back to bite you if the customer expects something else. Lastly keep in mind the key take-aways above, especially the performance one. 👍
Lastly… why would you ever investigate this? Well I have been working on a command line tool to search over text and code. I wanted it to be unicode aware, ran into performance issues with regular expressions in Go and decided to dive into learning how to do case insensitive searches while supporting unicode… now I am in awe at how anything actually works.
HN Comments https://news.ycombinator.com/item?id=23524400