UPDATE 2025-05-19
Somewhat un-suprisingly AWS has closed the loophole that I was exploiting for this https://aws.amazon.com/service-terms/#30._AWS_Lambda and as such compiling data into your lambda for “free” storage is no longer allowed. As such bonzamate.com.au in its current iteration has been shut down.
Watch this space however! I have some ideas on how to bring it back, albeit in a different form.
TL/DR I wrote an Australian search engine. You can view it at bonzamate.com.au. It’s interesting because it runs its own index, only indexes Australian websites, is written by an Australian for Australians and hosted in Australia. It’s interesting technically because it runs almost entirely serverless using AWS Lambda, and uses bit slice signatures or bloom filters for the index similar to Bing. I also found out the most successful code I have ever written is PHP, despite never being a professional PHP developer.
If you like the content below, register your interest for a book on the subject https://leanpub.com/creatingasearchenginefromscratch/
The idea
So I am in the middle of building a new index for searchcode from scratch. No real reason beyond I find it interesting. I mentioned this to a work colleague and he asked why I didn’t use AWS as generally for work everything lands there. I mentioned something to the effect that you needed a lot of persistent storage, or RAM to keep the index around which is prohibitively expensive. He mentioned perhaps using Lambda? And I responded its lack of persistance is a problem… At that point I trailed off. Something occurred to me.
Lambda’s or any other serverless function on cloud work well for certain problems. So long as you can rebuild state inside the lambda, because there is no guarantee it will still be running next time the lambda executes. The lack of persistance is an issue because modern search engines need to have some level of it. You either store the index in RAM, as most modern search engines do, or on disk.
Without persistance it makes lambda a non starter. But, there is a saying in computing.
Never do at runtime what you can do at compile time.
I decided to see how far I can take that idea, by using AWS Lambda to build a search engine. How do we get get around the lack of persistance? By baking the index into the lambda themselves. In other words, generate code which contains the index and compile that into the lambda binary. Do it at compile time.
The plan, is then to shard the index using individual lambda’s. Each one holds a portion of the index compiled into the binary that we deploy. Then then we call each lambda using a controller which invokes all of them, collects all the results, sorts by rank, gets the top results and returns them.
Why multiple lambdas? Well we are limited to 50 MB per lambda after it is zipped and deployed into AWS, so there is an upper limit on the size of the binary we can produce. However, we can scale out nicely to 1,000 lambda’s (by default in a new AWS account) so assuming we can stuff ~100,000 documents into a lambda we could build an index containing ~100,000,000 pages, on the entry level AWS tier. Assuming Amazon didn’t stop you it should be possible to grow this sort of index to billions of pages too as lambda does scale out to 10’s of thousands of lambdas, although I suspect AWS might have something to say about that.
The best part about this is that it solves one of the big problems with building a search engine. That problem is that you need to pay for a heap of machines to sit there doing nothing up till someone wants to perform a search. When you first start your search service nobody is using it so you have this massive upfront cost that sits idle most of the time. With lambda, you pay nothing unless it is being used. It also scales so, should you become popular overnight in theory AWS should deal with the load for you.
Another benefit here is that it means we don’t need to pay for the storage of the index because we are abusing lambda’s size limits to store the index.
AWS by default gives 75 GB of space to store all your lambda’s, but remember how I mentioned that the lambda is zipped? Assuming a 50% level of compression (and I think im low-balling that value) we get an index of 150 GB for free in the default AWS tier. That’s probably a default size as well, and could be raised.
That should be enough for a proof of concept. In fact looking at the free tier limits of AWS…
AWS Lambda 1,000,000 free requests per month for AWS Lambda
AWS Lambda 400,000 seconds of compute time per month for AWS Lambda
It will probably slide under the AWS Lambda Free tier as well for running even if we try many thousands of searches a month. If not, perhaps AWS will reach out and offer me some credits for being such a good sport, so I can iterate on the idea and build it out further.
Hey AWS, im doing something crazy! You know my number. So call me maybe?
Incidentally searching around for prior art I found this blog post https://www.morling.dev/blog/how-i-built-a-serverless-search-for-my-blog/ about building something similar using lucene, but without storing the content and only on a single lambda.
As for why AWS? No real reason other than I am most familiar with their platform. This should work on Google or Azure, although its debatable if you should build a search engine on a platform that is run by a company that has its own. As for language choice, I went with Go. The reasons being I am familiar with it, its reasonably fast, but most importantly it compiles quickly, which is important when you are getting the compiler to do more work, and should speed up the index update time.
Proving the theory
The first thing to do was see if this was even possible.
So the first thing I considered was putting content directly into lambda’s, and then brute force searching across that content. Considering our guess of storing ~100,000 items in a lambda, a modern CPU brute force string searching in memory should return in a few hundred milliseconds. Modern CPU’s are very fast.
So I tried it. I created a Go file with 100,000 strings in a slice, and then wrote a simple loop to run over that performing a search. I used a library I had written about a year ago https://github.com/boyter/go-string to do this which provides faster case insensitive search for string literals than regex.
Alas I underestimated how weak the CPU allotted to a lambda is, and searches took several seconds. Even increasing the RAM to improve the CPU allotment didn’t really help. My fallback plan was to embed an index into the lambda, allowing for a quick scan over that index before looking at the content directly.
As I was already working on a replacement index for searchcode.com I have the majority of the code needed for this. I had been working on a bloom filter based index based on the ideas of bitfunnel which was developed by Bob Goodwin, Michael Hopcroft, Dan Luu, Alex Clemmer, Mihaela Curmei, Sameh Elnikety and Yuxiong He and used in Microsoft Bing https://danluu.com/bitfunnel-sigir.pdf. For those curious the videos by Michael are very informative, you can find the links to them here and here.
This technique lends itself pretty well to what I am attempting to do, because ultimately it’s just an array of 64 bit integers you scan across, making it trivial to write this out into a file which you then compile. Its also already compressed ensuring we can stay under our 50 MB limit while storing a lot of content. Lastly the actual code to do the search is a simple loop with some bitwise checks. Far easier to deal with than a skiplist, which would need to be written into code.
Because I am embedding this directly into code I simplified the ideas that bitfunnel uses so it’s not a full bitfunnel implementation. One thing I did do was rotate the bit vectors to reduce the memory lookups. The index itself is written out as a huge slice of uint64’s. This slice always has a length which is a multiple of 2048. This is because the length of the bloom filter for each document is 2048 bits. Each chunk of 2048 uint64’s holds the index for 64 documents filling all of the uint64 bits, right to left.
I did not use a frequency conscious bloom filter for this implementation, nor the higher ranked rows that are one of the main bitfunnel innovations. This greatly simplifies the implementation, and results in a beautifully simple core search algorithm.
func preSearch(queryBits []uint64) []uint64 {
var results []uint64
var res uint64
for i := 0; i < len(bloomFilter); i += 2048 {
res = bloomFilter[queryBits[0]+uint64(i)]
for j := 1; j < len(queryBits); j++ {
res = res & bloomFilter[queryBits[j]+uint64(i)]
if res == 0 {
break
}
}
if res != 0 {
for j := 0; j < 64; j++ {
if res&(1<<j) > 0 {
results = append(results, uint64(64*(i/2048)+j))
}
}
}
}
return results
}The result of the above returns a list of interesting document id’s which can then be brute force checked for the terms we believe are in there. We only believe because of the false positive property that bloom filters have. Bloom filters by default produce false positive results, but the above is fast enough to run in a few milliseconds cutting down on the total number of documents we need to inspect to a manageable level.
Once the candidates are picked, they are then processed using the brute force search I tried before, and those results are then passed off for ranking. Once that’s done they are sorted, and the top 20 results have a snippet created and the result returned.
Checking cloudwatch with the above implemented shows the following runtime’s for a variety of searches being run, on a lambda allocated with 1024 MB of RAM.
2021-09-13T14:33:34.114+10:00 Duration: 142.89 ms Billed Duration: 143 ms
2021-09-13T14:34:26.427+10:00 Duration: 6.44 ms Billed Duration: 7 ms
2021-09-13T14:35:15.851+10:00 Duration: 3.40 ms Billed Duration: 4 ms
2021-09-13T14:35:28.738+10:00 Duration: 1.10 ms Billed Duration: 2 ms
2021-09-13T14:35:44.979+10:00 Duration: 6.11 ms Billed Duration: 7 ms
2021-09-13T14:36:15.089+10:00 Duration: 70.31 ms Billed Duration: 71 ms
The larger times are usually caused by a search for a really common term, which produces more results, hence more work. This can actually be cut down with some early termination logic, which I implemented later. Keep in mind that the above times include ranking and snippet extraction as well and the result is ready to show to the user. Its not just the time for the core search.
It keeps getting mentioned to me that you can use docker images with lambda to get 10 GB of storage. I did consider this, but my early experiments suggested that there isn’t enough CPU in lambda to use the storage. Besides this feels like a nice hack :)
Early Termination Logic
So early termination was something I was aware of but never really investigated. I assumed it was a simple case of,
We have 1,000 results and you are only going to look at 20 of them so lets stop processing and return what we have already
Then I started reading about early termination algorithms and stumbled into a huge branch of research I never knew existed. A few links about it that I found are included below.
- https://www.usenix.org/system/files/conference/atc18/atc18-gong.pdf
- https://github.com/migotom/heavykeeper/blob/master/heavy_keeper.go
- https://medium.com/@ariel.shtul/-what-is-tok-k-and-how-is-it-done-in-redisbloom-module-acd9316b35bd
- https://www.microsoft.com/en-us/research/wp-content/uploads/2012/08/topk.pdf
- http://fontoura.org/papers/lsdsir2013.pdf
- https://www.researchgate.net/profile/Zemani-Imene-Mansouria/publication/333435122_MWAND_A_New_Early_Termination_Algorithm_for_Fast_and_Efficient_Query_Evaluation/links/5d0606a5a6fdcc39f11e3f0f/MWAND-A-New-Early-Termination-Algorithm-for-Fast-and-Efficient-Query-Evaluation.pdf
- https://dl.acm.org/doi/10.1145/1060745.1060785
I didn’t know there was so much research about this. The more you learn the more you realise you know so little. Seems a lot of people get a Ph.D. out of research in this area. I quickly backed away from some of the techniques above (they are way above my pay grade) and just wrote a simple implementation to bail out once it had enough results, but with a guess as to how many would have been found had we kept going.
With this done, searches worked well enough in a lambda, returning in under 100 ms for most searches I tried. So I moved on to the next few problems.
Getting Source Data
There are a heap of places to get a list of domains these days, which can serve as your seed list for crawling. People used to use DMOZ back in the day, but it no longer exists and its replacement does not offer downloads.
The following page https://hackertarget.com/top-million-site-list-download/ has a list of places you can pull top domains from, helping build this out.
Considering all of the media search laws going on in Australia (at the time I started toying with this) I realized I can make this an Australian search engine, and maybe get some attention. There are some other advantages to this as well. The first being that because you need to have an ABN to get a .au domain it naturally lowers the amount of spam I would need to deal with. It also ensures that there is a subset of domains thats actually feasible to crawl in reasonable time frame.
So I picked a few sources from the lists in the above link, then pulled out all of the Australian domains (those ending in .au, but I should include .sydney and .melbourne in there) and created a new list. This produced 12 million or so domains ready to be crawled and indexed.
Crawling Some Data
Crawling 12 million domains seems like a trivial task, up until you try it. A million pages is something you should taco bell program, but more than than needs a bit more work. You can read up on crawlers all over the internet, but I was using Go so this link https://flaviocopes.com/golang-web-crawler/ seemed fairly useful. Further reading suggested using http://go-colly.org as it is a fairly decent Go crawler library. I took this advice and wrote a quick crawler using Colly, but kept running in memory issues with it. Probably due to how I used it, and not a fault of the Colly itself. I tried for a bit to resolve the issues, but in the end gave up. Colly is one of those tools I think I need to learn more about, but in this case I just want to move on.
So I wrote a custom crawler. I locked it to only downloading for a single domain I supplied. I then had it process the documents as it went to extract out the content I wanted to index. This content I kept as a collection of JSON documents dumped one per line into a file, which I then stuffed into a tar.gz file for later processing and indexing.
An example prettified truncated document follows. The content you see there is what is actually passed into the indexer, and potentially stored in the index.
{
"url": "<https://engineering.kablamo.com.au/>",
"title": [
"Kablamo Engineering Blog"
],
"h1": [
"Lessons Learnt Building for the Atlassian Marketplace",
"What I Wish I Knew About CSS When Starting Out As A Frontender",
"How to model application flows in React with finite state machines and XState"
],
"h2h3": [
"Our Partners"
],
"h4h5h6": null,
"content": [
"THE BLOG",
"Insights from the Kablamo Team.",
"28.7.2021 - By Ben Boyter"
]
}
There are a few problems with this technique. The first is that by discarding the HTML if you have a bug in your processing code you need to re-crawl the page. It also adds more overhead to the crawler since part of the index process is is being done in the crawler. Crawlers are normally very CPU light but bandwidth heavy.
The advantage however is that the indexing can be a little faster, and it reduces the disk space needed to store content before indexing. The disk space reduction is not trivial, and can be something like 1000x depending on the content on the page. For the samples I tired it was a 50x reduction on average.
I then set my crawlers off, firstly going for breadth by getting a few and getting as many of those 12 million domains as I could, and then again with depth to pull more pages. With the files ready I was ready to index. I ran the crawlers mostly on my own desktop, and on one of the servers for searchcode.
Crawling incidentally I think is the biggest issue with making a new search engine these days. Websites flat out refuse to support any crawler than Google, and cloudflare and other protection services and CDN’s flat out deny access to incumbents. It is not a level playing field. I would actually like to see some sort of communal web crawl supported by all web crawlers that allows open access to everyone. The benefits to websites would be immense as well, as they could be hit by a single crawler, rather than multiple, and bugs could be ironed out.
Ranking
Ranking is one of those secret sauce things that makes or breaks a search engine. I didn’t want to overthink this so I implemented BM25 ranking for the main ranking calculation. I actually implemented TF/IDF as well but generally the results were similar for the things I tried. I then added in some logic to rank matches in domains/urls and titles higher than content, penalize smaller matching documents and reward longer ones (to offset the bias thats in BM25).
Ranking using BM25 or TF/IDF however means you need to store global document frequencies. You also need average document length for BM25. So those are two other things that need to be written into the index. Thankfully they can be calculated pretty easily at index time.
The algorithm is fairly easy to code up,
// defaults for BM25 which provide a good level of damping
k1 := 1.2
b := 0.75
for word, wordCount := range res.matchWords {
freq := documentFrequencies[word]
tf := float64(wordCount) / words
idf := math.Log10(float64(corpusCount) / float64(freq))
step1 := idf * tf * (k1 + 1)
step2 := tf + k1*(1-b+(b*words/averageDocumentWords))
weight += step1 / step2
}Of course everyone knows that PageRank by Google is what propelled Google to the top of the search heap… Actually I don’t know how true that is and I suspect that speed and not being a portal helped, but regardless, pagerank requires processing your documents multiple times to produce the rank score for the domain or page. It takes a long time to do this, and while the whole thing beautiful mathematically, its not very practical especially for a single person working on this in their spare time.
Can we find an easier way to do this? Some shortcut? Well yes. Turns out that all of the document sources where I got the domains, list those domains in order of popularity. So I used this value to influence the score giving a “cheap” version of pagerank. Adding the domain popularity into the index when building it provides some pre-ranking of documents.
I plan on making this able to be turned off at some point so you can just rank based on content, but for most general searches this really improves the results. I did however add the ability to flip between BM25 and TF/IDF for general searches which could be interesting for some people. The ability to tweak the ranking algorithms on the fly is something I want to explore more as well as I think handing the power back to the user is a good thing.
Note that ranking is especially important when working with bit vector or bloom filter search engines because of the false positives. The ranking helps drop these false positives to the bottom of the results, and so its less of an issue in practice than you may think.
Adult Filter
Something all search engines need to deal with is identifying and filtering adult content. I don’t feel like getting a PHD in deep learning to achieve this, so I went for a very simple solution.
Given a document, if any run of 4 out of 5 words, ignoring words of 2 characters or less, are considered “dirty” which is they have a match in a collection of dirty terms, then mark the page as having adult content. This is very similar to how Gigablast does its adult filter, however without any obscene words that it uses to instantly mark a page as adult. I also used a much larger group of dirty words.
Note this isn’t meant to be a moral crusade. I don’t care what you are searching for. It’s just something thats annoying to see in your search results at times and something users ask for almost instantly.
What did occur to me though was that search engines by knowing adult content and filtering it out, could also offer an option to search ONLY adult content. They don’t for some reason. It is however useful for finding false positive matches however, so I added the ability to filter either way, or remove the filtering totally for mixed results. You can see it using the advanced option selector.
Snippet Extraction AKA I am PHP developer
Snippet’s are those extracts of text from the main document that you see in your search results. Its actually one of the reasons that Google did better than so many other search engines at the time because it provided snippets taken from the text while others such as Inktomi did not. Some credit this difference as being one of the factors in Google winning the search engine wars.
Inktomi didn’t have snippets or caching. Our execs claimed that we didn’t need caching because our crawling cycle was much shorter than Google’s. Instead of snippets, we had algorithmically-generated abstracts. Those abstracts were useless when you were looking for something like new ipad screen resolution. An abstract wouldn’t let you see that it’s 2048×1536, you’d have to click a result.
Thinking about that, if I used algorithmically-generated abstracts I could make the index even smaller, and put more results into my lambda. Something to consider for deeper web results perhaps?
Anyway this is something I got way deeper into than was probably needed. Thought I did find it immensely fun.
The extraction of snippets from some text is one of those problems I naively assumed would be simple to solve. I did have a small reason to assume this however as I had previously written about building one in PHP which was based on an even older stackoverflow answer of mine. It was based on the techniques used in an even older PHP crawler/indexer project named Sphider.
So I quickly ported it to Go to see how it would perform. For small snippets it continued to work reasonably well giving reasonable results. For multiple terms, especially those spread out in large documents it was not producing the results I wanted. In fact it was so bad as to snip around content that had no terms in it. Clearly not good enough.
Annoyingly snippet extraction is a “fuzzy code” problem, with no obvious 100% correct solution you can work towards. What is most relevant to my search might not be what you expected. It also means that coming up with some test cases is problematic, as the moment you solve one you might break another. In any case I decided that my test case for snippet extraction would be based on Jane Austen’s Pride and Prejudice which I admit to knowing more about than I probably should. One of the main test cases I wanted to work was a search for ten thousand a year which should return one of two snippets. The reason being that the terms occur a few times in the book as is, with the rest scattered around and the letter a appearing all over the place. The two most relevant portion of the text in my opinion are,
features, noble mien, and the report which was in general circulation within five minutes after his entrance, of his having ten thousand a year. The gentlemen pronounced him to be a fine
and
it. Dear, dear Lizzy. A house in town! Every thing that is charming! Three daughters married! Ten thousand a year! Oh, Lord! What will become of me. I shall go distracted.”
For this case either is an acceptable answer for me, and I can live with a word or two being included or excluded on the edge. Although in an ideal world I would prefer it to be case sensitive when ranking them and produce the first result as a slight preference over the second. At this point I started searching around to find out what existing research was out there regarding snippet extraction and see and how this problem had already been solved. This included looking at existing code bases. I was aware that the PHP Relevanssi plugin probably had some implementation that might be worth looking at and started there.
Well blow me down. Turns out the small chunk of PHP code I wrote in anger to produce snippets was picked up by a bunch of PHP projects including Relevanssi Bolt and Flowpack. For Relevanssi turns out I am even mentioned by name in the credits of the release of both the free and paid for versions.
What’s interesting to me about this is that Relevanssi (as wordpress plugin) has over 100,000 installs. Which means it is probably the most successful code I have ever written in terms of use. Also interesting is that it is written in PHP. I have almost never been paid to write PHP. Certainly my professional PHP code days can be counted on both hands. I wonder if thats something I should put on my resume?
Anyway I had already ruled out this code as not being good enough. As such I expanded my search. Here is a collection of links I found relevant to this specific problem, and a cached version as PDF’s just in case there is some link rot and you cannot get that document you want.
- Practical Relevance Ranking for 11 Million Books, Part 3: Document Length Normalization. [Cached PDF]
- UnifiedHighlighter.java [Cached PDF]
- Package org.apache.lucene.search.vectorhighlight [Cached PDF]
- How scoring works in Elasticsearch [Cached PDF]
- 6 not so obvious things about Elasticsearch [Cached PDF]
- Elasticsearch unified-highlighter doc reference [Cached PDF]
- Elasticsearch unified-highligher reference [Cached PDF]
- Extracting Relevant Snippets from Web Documents through Language Model based Text Segmentation [Cached PDF]
- Keyword Extraction for Social Snippets [Cached PDF]
- Fast Generation of Result Snippets in Web Search [Cached PDF]
- A LITERATURE STUDY OF EMBEDDINGS ON SOURCE CODE [Cached PDF]
- The smallest relevant text snippet for search results [Cached PDF]
- C# Finding relevant document snippets for search result display [Cached PDF]
- Given a document, select a relevant snippet [Cached PDF]
- Reverse Engineering Sublime Text’s Fuzzy Match [Cached PDF]
Of the above documents the most promising to turned out to be the information I found on rcrezende.blogspot.com and the source code of Lucene. I took some of the ideas from the descriptions of both and then implemented an algorithm fused with the scoring techniques of the reverse engineered Sublime Text fuzzy matching.
I had previously worked on this for another project (which I should finish one of these days). The algorithm is fairly well documented so for those interested please look at the source code https://github.com/boyter/cs/blob/master/processor/snippet.go to see how it works in depth. It’s not 100% the same as the one I used, but very close.
The results for our sample search “ten thousand a year” returns the below snippet,
before. I hope he will overlook it. Dear, dear Lizzy. A house in town! Every thing that is charming! Three daughters married! Ten thousand a year! Oh, Lord! What will become of me. I shall go distracted.” This was enough to prove that her approbation need not be
For “stranger parents” the result is what I consider perfect.
An unhappy alternative is before you, Elizabeth. From this day you must be a stranger to one of your parents. Your mother will never see you again if you
Another good example which has multiple candidates, “poor nerves”.
your own children in such a way? You take delight in vexing me. You have no compassion for my poor nerves.” “You mistake me, my dear. I have a high respect for your nerves. They are my old friends. I have heard you mention them with consideration these last
To save you a click, it works by passing the document content to extract the snippet from and all of the match locations for each term. It then looks though each location for each word, and checks on either side looking for terms close to it. It then ranks on the term frequency for the term we are checking around and rewards rarer terms. It also rewards more matches, closer matches, exact case matches and matches that are whole words. The results turned out to be better than expected for my sample text of Pride and Prejudice, and so I was happy to move on.
Indexing
So the indexing step is the final step needed to have something working end to end. To do it, I wrote a program that firstly walks all of the files downloaded. It reads the number of lines in each file and then groups files together into batches trying to find a collection of domains that when written together to disk get as close to the maximum size AWS allows for a lambda. This works out to be about a 150 MB of Go code, or about 70,000 documents. When compiled and zipped this tends to get very close to the 50 MB limit.
When a batch is found it is handed off to be processed. At this point the files are read, and the documents inside run though a process which analyses them, producing tokens ready to be indexed and determines a score for it.
The processing does things like looking at all of the titles, picking the first to be indexed. If a title is missing then it looks at H1 tags. Duplicate titles and H1’s for the same domain are removed and regular content is tokenized and stemmed.
Then the tokens are checked to try and identify the document category and determine if it contains adult content or not. The final step is to index the batch and then write it out as a file.
With that all done, I write out the block. It’s actually writing out to a Go file than can then be indexed. Its fairly ugly using strings, but works well enough.
sb.WriteString(fmt.Sprintf(`var averageDocumentLength float64 = %d`, averageDocumentLength))
sb.WriteString(`var documentFrequencies = map[string]uint32{`)
for k, v := range newFreq {
sb.WriteString(fmt.Sprintf("\"%s\": %d,", k, v))
}
sb.WriteString("}")
sb.WriteString("var bloomFilter = []uint64{")
for _, v := range bloom {
sb.WriteString(fmt.Sprintf("%d,", v))
}
sb.WriteString("}")
*,* = file.WriteString(fmt.Sprintf(`{Url:"%s",Title:"%s",Content:"%s",Score:%.4f,Adult:%t},`,
res.Url,
res.Title,
res.Content,
res.Score,
res.Adult))Once the block is written, it is then compiled and uploaded into AWS replacing the previous lambda. If its a new lambda, its deployed into AWS and the controller lambda has its environment variables update to know about the new lambda, at which point new searches will hit it and the index grows.
The result? Something like the below, where you can see multiple lambda’s deployed.
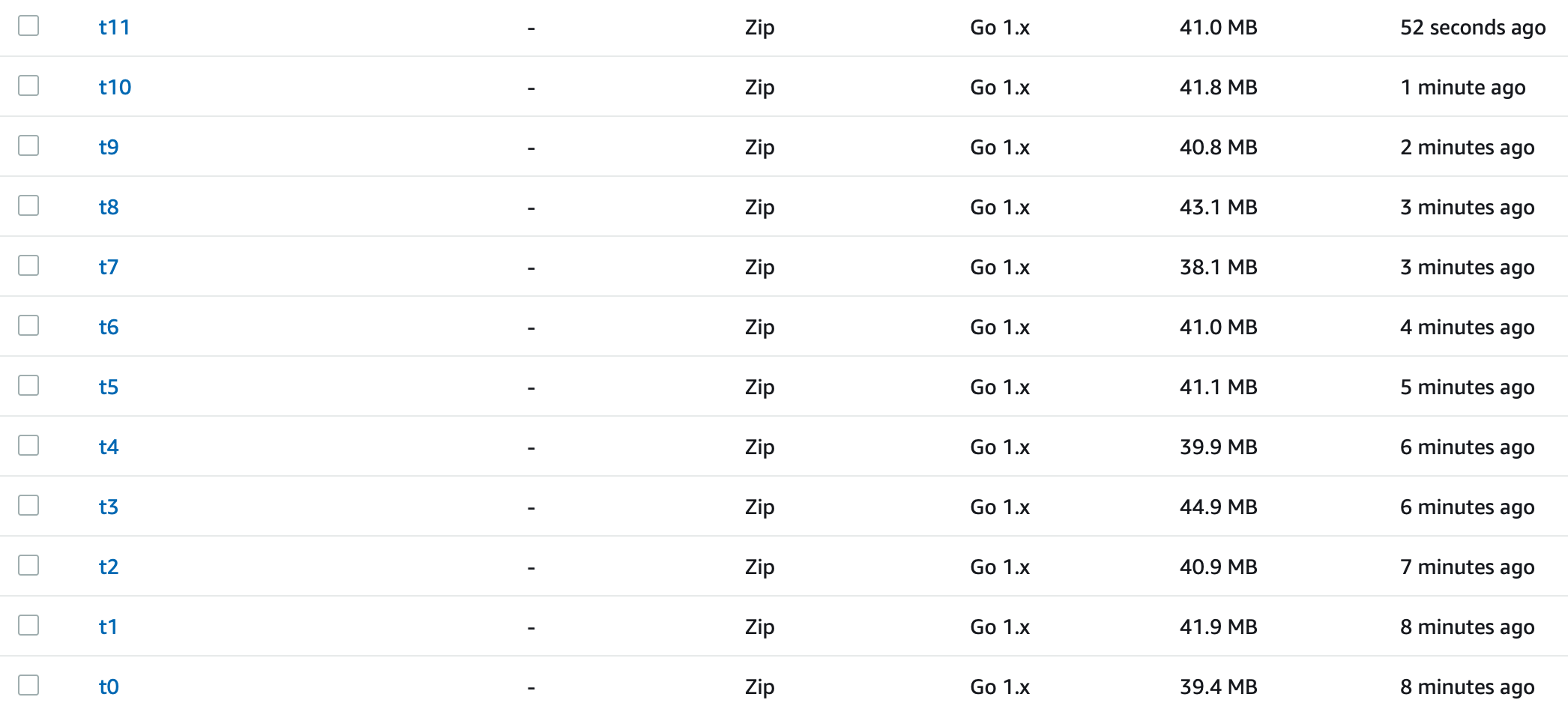
There is some room for improvement here to make more optimal use of the lambda size. I purposely made the indexer not push the limits as it’s size estimation is a little off and it can make mistakes. As such it tends to aim for lambdas about 40 MB in size. This should be easy to resolve when I get the time and should allow the number of documents stored in each lambda to increase by about 15%. This would also lower the number of deployed lambdas.
Putting it all together
I have been a bit remiss in my devop’s skills recently. The last time I seriously touched cloudformation I was using JSON though a custom template processor (don’t laugh we all do it at some point). So I used this as an opportunity to get back into the swing of things.
The design is as follows.
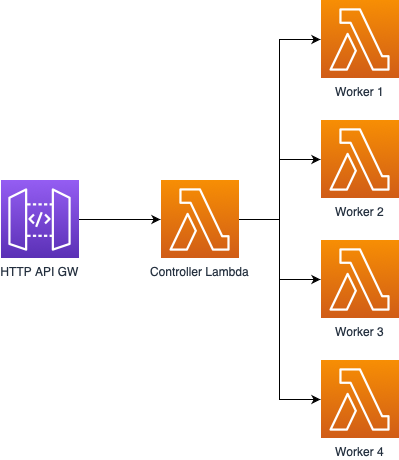
API Gateway fronts a single controller lambda which calls multiple workers as configured in its environment variables. The workers contain the index, and when passed a query they search over their content finding matches, ranking them and then returning the top 20 results. The controller waits for all the results to return, joins them together, re-sorts and sends the top results back.
Usually having a lambda call another lambda is a major anti pattern, and it could probably be removed. I could just call the lambdas directly from the HTTP server at some point, although this way I get an API I can use for other purposes, and it decouples the index from the web server which feels nice.
Deploying the API Gateway and controller is done through cloudformation. Workers are deployed directly using the AWS API. This is done because they need to be updated and created fairly often and cloudformation was just too slow to achieve this.
Lastly I also needed a website to serve it all up. I want to protect index itself, so rather than fire AJAX requests at the endpoint allowing anyone access, I quickly coded a small HTTP server which calls back to the endpoint and performs a search. This is the only non serverless portion of the site, and only because I was feeling lazy. I then turned to MVP CSS to make it not offensively ugly and produced the following.

Since I run my blog (this one) on a VPS in Australia, and use Caddy as the main server, I just added a new entry there and pointed DNS at it. I also added some IP restrictions (want to avoid being spammed) and a cheap cache for repeated queries.
Seeing as I was going to the effort, I also added a quick info box output similar to the ones you see on Bing/Google/DuckDuckGo which present some information for you based on wikipedia entries. Same idea as the workers, with the content compiled into a binary.
I pulled down the wikipedia abstracts data set and then kept anything mentioning Australian content. The abstracts data set is actually pretty bad with lots of broken content so I had to put some effort in to filter that out. I have plans to try processing wikipedia itself at some point to produce this in the future.
The final thing needed to be a legitimate search engine was a news feed. Because I didn’t want to run afoul of the news payment laws that passed in Australia I only hit independent and publicly funded news organizations. It runs on a schedule every 15 minutes pulling a variety of RSS feeds, sorting them and saving the content to S3 and to a global value. The lambda when called looks at the global value, and if something is there returns that, otherwise it fetches the content from S3, sets the global value and returns it. It also accepts the search values so you can filter the news down.
Results
Well firstly, building a search engine is hard. Runtime systems are hard. Algorithms are hard. You have to do both. In addition you need to build a crawler which is being fought against by the modern internet, design an index format, ensure its fast and ensure everything scales. You need to work on ranking algorithms, for which all the big players have buildings full of very smart people working on. Heck they don’t even know how their ranking works since they are trained using AI these days. You need to fight against spammers and SEO optimizers, categorize text pages (a very hard problem) while fighting against the constraints of time.
Heck even picking the snippet of text to plonk on the page is a hard problem. While any of the above issues are possible to have solved quickly by the most junior member of your team solving them in a way that people actually expect is indeed very hard.
Oh and bandwidth limits are a big blocker. If you behave like a good internet bot, respecting HTTP 429 and crawling gently, you need a LOT of machines to do it effectively. Something like common crawl could help with this, but they don’t refresh the crawl very often, so it seems to be more useful for research than a search engine. Although combining it with freshly crawled results could produce a good result and is something I am now considering.
Thankfully using lambda takes away a some of the hard issues for you. So AWS working as expected. Scale is less a problem for instance. By limiting myself to Australian sites, worrying about global DNS, local servers and such is less of an issue, since I only need to worry about my primary audience.
Speaking of lambda, as I write this there are 250 lambdas powering the search. The index itself is about 12 million pages. Improvements to the indexing code could reduce that number of lambdas to about 200 given some effort, so it looks like 100 million documents using the full 1,000 lambdas seems possible, but more likely it would be close to 80 million when done. The only reason I have not done so is since I am still waiting on my crawlers.
Assuming I wanted to move to 1000 lambda’s I would modify the design having 200 or so lambdas per controller. This seems like a reasonable amount to control per lambda, as I suspect having 1000 under one might cause serious overhead problems. Just a matter of spinning up another stack though which is pretty easy.
Anyway you can try the result for yourself at Bonzamate The name came to me when I was looking at possible domains to host under and seemed to be suitably Australian.
For those who don’t speak Aussie it means “first rate” or “excellent” + mate. It’s something you might say to your buddies.
“How was the footy?”
“It was bonza mate!”
It also passes my test of being able to explain to someone over the phone, which none of my other choices did.
Anyway, while looking to write a post about search engines that run their own index I found this page A look at search engines with their own indexes which is pretty much what I would have liked to have written. It has some interesting search tests, which alas aren’t really applicable to my search since its not general purpose. Or rather region specific, making it hard to reuse the same criteria.
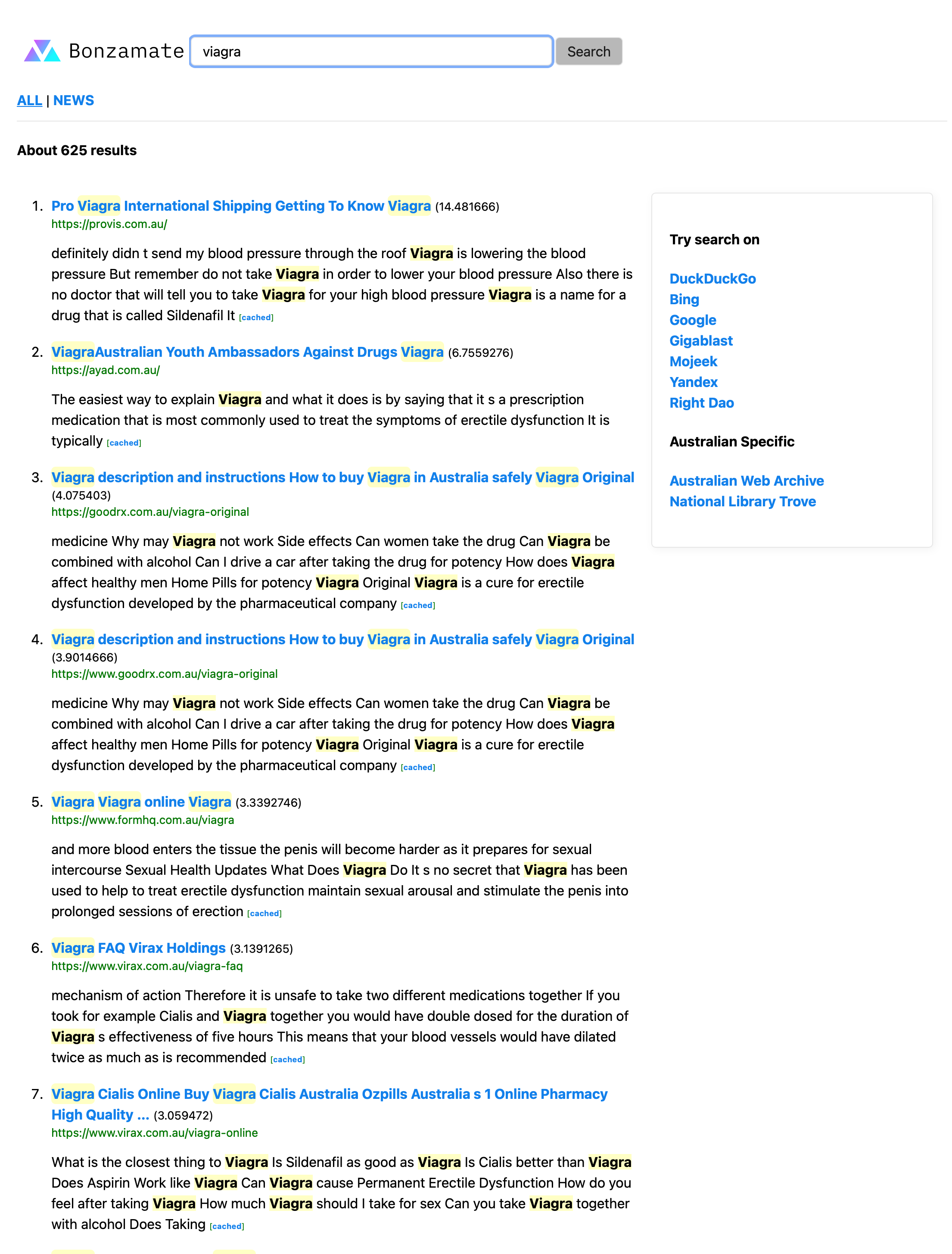
So I came up with some of my own tests. The first being a search I try on every search engine. A search for viaga. The reason being that its usually highly SEO gamed and full of spam results. The results? Honestly not too bad. No real spam, although there are highly SEO optimized pages in there.
How about a search for something a little more interesting, bushfire prediction. I would expect to get content from the CSIRO and universities for this one. Which is what is found, and useful to me personally.
A vanity search for myself turned up the exact pages I would have expected, ben boyter producing a blog post I wrote for work about the Atlassian Marketplace and GopherCon Au where I was one of the speakers.
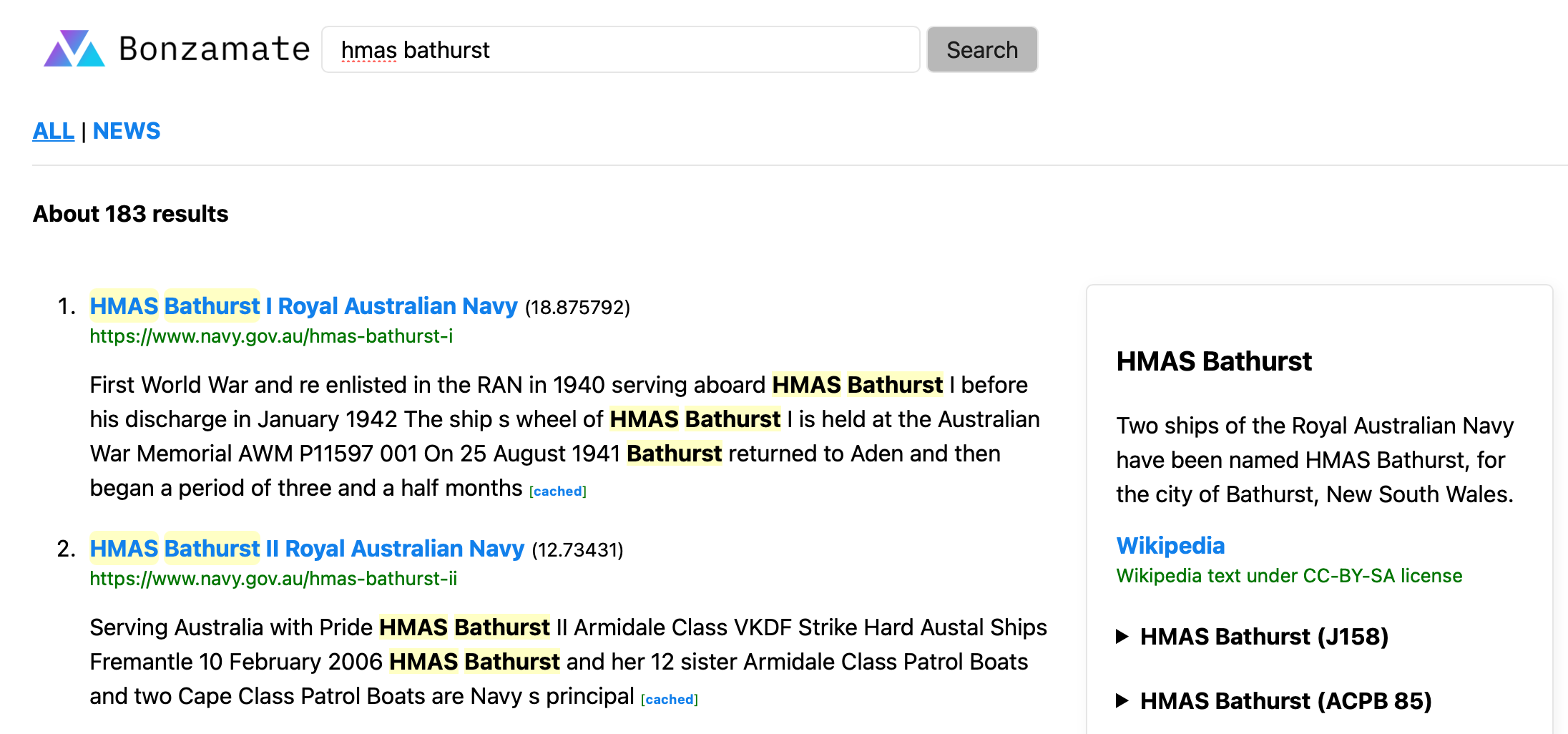
Side panel information results appear from time to time as well like this example hmas bathurst with relevant results in the search as well. Searches for other navy ships and boats seem quite good such as hmas onslow.
Searches for websites I commonly check, https://bonzamate.com.au/?q=ozbargain https://bonzamate.com.au/?q=sbs https://bonzamate.com.au/?q=abc worked as expected showing the site I was looking for at or near the top of the results page.
A few other interesting searches I tried that seemed to produce results I would expect,
- https://bonzamate.com.au/?q=australia+united+party
- https://bonzamate.com.au/?q=%22craig+kelly%22
- https://bonzamate.com.au/?q=charles+sturt+university
- https://bonzamate.com.au/?q=bar+luca
- https://bonzamate.com.au/?q=best+burger+melbourne
- https://bonzamate.com.au/?q=pfizer+research
- https://bonzamate.com.au/?q=tom+glover+pfizer
- https://bonzamate.com.au/?q=norfolk+island
- https://bonzamate.com.au/?q=having+baby+in+canberra
- https://bonzamate.com.au/?q=asian+history
What I do find about the above searches is that they are as you would expect Australian centric. So searching for asian history produces results that finds this page, which is something I wouldn’t find as easily on Google/Bing even with the region set.
So what about that porn filter? Well a search for porn itself https://bonzamate.com.au/?q=porn produces nothing that I would describe as porn. Books about food porn and such. Trying some other search for swear words and such seemed to work as expected, so that seems reasonable. Of course you can always switch into mixed results, or inverse the search to only browse them.
Searches for news are useful too, although as the results being ephemeral are harder to link to. Please forgive the subject choice, but I am fairly confident at time of posting they will have something to show.
- https://bonzamate.com.au/news/?q=covid
- https://bonzamate.com.au/news/?q=wine
- https://bonzamate.com.au/news/?q=china
- https://bonzamate.com.au/news/?q=darwin
Clearly there are a few bugs. The highlighting of quoted search for example does not work, although the search does do it as expected. There are some issues with duplicate content as both www and non www are treated as different domains, which they are but anyway. Something I will get around to resolving later.
For those trying their own searches, remember that this harkens back to the days of old school keyword search engines. You type terms, and the engine matches only documents that contain those exact terms. There are no keyword substitutions such as converting pub chatswood into (pub || tavern || bar || nightclub || hotel) chatswood which is what happens in Google and Bing. Query expansion like this is something I would like to add as an option that can be controlled by the user, assuming of course I can find a decent list to allow this. Gigablast appears to have one, but it looks less than exhaustive mysynonyms.txt.
The Future?
In February 2021 the Australian Greens Party called for a publicly owned search engine to be created and be independent and accountable like the ABC. [[1]]https://www.itnews.com.au/news/the-greens-want-a-publicly-owned-search-engine-to-replace-google-560574](https://www.abc.net.au/radio/newsradio/greens-call-for-publicly-owned-search-engine/13115664)
This was generally mocked by many Australians, including the media which had forced Google’s hand into threating to leave Australia by lobbying for the government to make Google and Facebook to pay for news content. [3]
Personally, I and others such as Matt Wells of Gigablast believe that nationalized search is important. Or at least competition, with local players. The only search engines really used in Australia are all owned by the USA. With so few indexes, the main ones being Google, Bing and Yandex (GBY), and the inability of meta-search engines to mix and match results from multiple indexes the question has to be asked, “What are Google/Bing NOT showing you today?”.
However the question remains, could a search engine be implemented by an independent organization? Previously this approach has failed in Europe and Russia with Quaero and Sputnik. However the use of private enterprise and publicly owned companies can produce excellent results, and possibly even in the search space.
I personally have some experience in this, having been one of the main developers at Kablamo who worked on the ABC’s Archive which you can learn about on youtube. You can skip to the exact point the CoDA search is demoed here. A perfect fusion of a publicly owned chartered organization and private enterprise bringing their own expertise.
Of course general purpose search is an entirely different ball game to CoDA. But if a single person, working in their spare time with zero budget, and no formal search engine experience can create what feels like a reasonable POC it seems possible that with a bit of funding and time something better could be done. Australia is an exporter of research talent. Heck one of the better enterprise paid for search engines out there Funnelback was jointly developed with the CSIRO and ANU, so it does not appear to be a lack of talent issue in Australia. I would love there to be more competition in the search space, and I would love to see an Australian search engine be part of it.
Regardless I plan on iterating on Bonzamate as I get more time. I really want to fix the info box to pull in all of the Australian wikipedia content, and I want to grow the index more, and improve the ranking. Having site filters and categories are also on the list of things I would like to add. Fixing those annoying bugs is something on the list too.
This post has gone on long enough. Want your site indexed? Want to talk to me? What general information? Want to give me lots of money to build this out? Just want to hurl some abuse? Want access to the API’s (I might need to charge for this, but I 100% will allow remixing of results). Hit me up ben@boyter.org or via slack. You can also message me on twitter @boyter if you want to get an invite or just want to chat.