Update 2019-03-13
This is now part of a series of blog posts about scc Sloc Cloc and Code which has now been optimised to be the fastest code counter for almost every workload. Read more about it at the following links.
- Sloc Cloc and Code - What happened on the way to faster Cloc 2018-04-16
- Sloc Cloc and Code Revisited - A focus on accuracy 2018-08-28
- Sloc Cloc and Code Revisited - Optimizing an already fast Go application 2018-09-19
- Sloc Cloc and Code a Performance Update 2019-01-09
- Sloc Cloc and Code Badges for Github/Bitbucket/Gitlab
I thought I had finished with my code counter Sloc Cloc and Code (AKA scc) https://github.com/boyter/scc/ for a while. The what I had hoped to be final blog post about it https://boyter.org/posts/sloc-cloc-code-performance/ however did mention that the building of the language features in it were a cause of slowdown,
The trade off of building the trie structures when scc starts does slow down the application for smaller repositories such as redis. That said a slowdown of only 10 ms is probably worth it. Keeping in mind on linux that ~15 ms of overhead is usually the process starting, and that most people will not notice the difference between 15 ms and 30 ms for this sort of application, I think its an acceptable trade.
As it usually does I realized that perhaps I was thinking about it incorrectly. When scc started it would process all of the languages into the trie structures it needs in order to count code. However the majority of code repositories have say ten or so languages in them. With 220 languages supported scc was doing pointless work for over 200 languages every time it was run.
There are two ways to fix this. The first would be to build the structures and compile them into the application. This has the advantage of no processing overhead, but means its less flexible to make changes since you need to bake it into the application. The second is to only build the language features when required, or lazy load them when necessary, which is a much easier thing to implement, and what I did.
A few hours of fiddling around and I made the change and had a release. I ended up adding mutex locks around the hash that holds the language features. I did investigate using the Sync Map that Go added back in version 1.9 but it turned out this was actually slower then the few locks I added, so I stuck with those.
With the implementation done the results are quite good with the time down for every run compared to version 2.0.0. A quick example comparing 2.0.0 to 2.1.0 using the redis code-base.
Benchmark #1: scc-2.1.0 redis
Time (mean ± σ): 81.6 ms ± 5.0 ms [User: 173.8 ms, System: 265.4 ms]
Range (min … max): 75.5 ms … 97.1 ms
Benchmark #1: scc-2.0.0 redis
Time (mean ± σ): 124.4 ms ± 2.4 ms [User: 168.6 ms, System: 289.1 ms]
Range (min … max): 120.0 ms … 128.4 ms
With that done, I moved over to using my standard test suite to see how it performed against the other new code counters.
Benchmarks
All GNU/Linux tests were run on Digital Ocean 32 vCPU Compute optimized droplet with 64 GB of RAM and a 400 GB SSD. The machine used was doing nothing else at the time and was created with the sole purpose of running the tests to ensure no interference from other processes. The OS used is Ubuntu 18.04 and the Rust programs were installed using cargo install. The programs scc and polyglot were downloaded from github.
For further details about the benchmarks see https://boyter.org/posts/sloc-cloc-code-performance/
Tools under test
- scc v2.1.0 (downloaded from github)
- tokei v8.0.0 (compiled with Rust 1.31)
- loc v0.5.0 (compiled with Rust 1.31)
- polyglot v0.5.18 (downloaded from github)
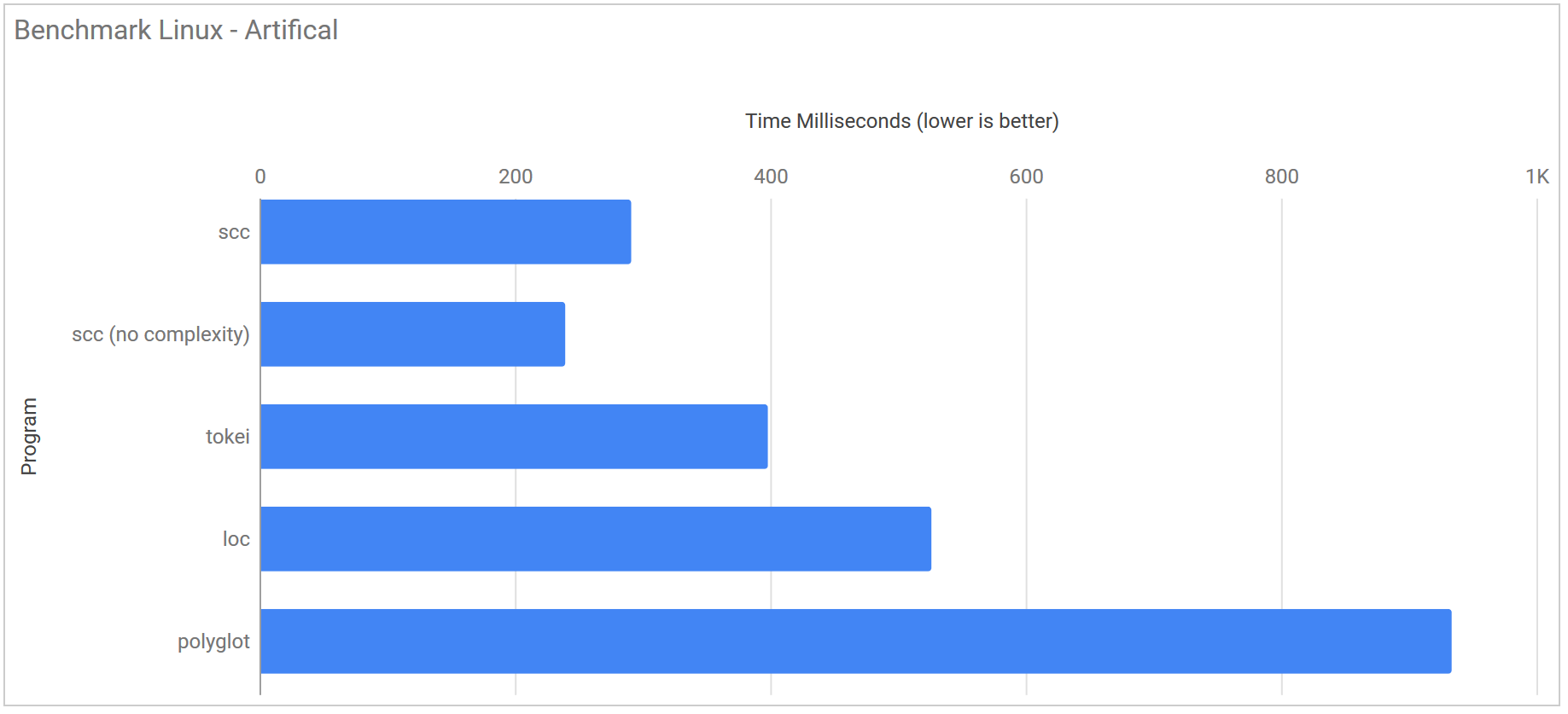
Artificial
| Program | Runtime |
|---|---|
| scc | 304.9 ms ± 15.8 ms |
| scc (no complexity) | 239.4 ms ± 8.7 ms |
| tokei | 392.8 ms ± 12.9 ms |
| loc | 518.3 ms ± 130.2 ms |
| polyglot | 990.4 ms ± 31.3 ms |
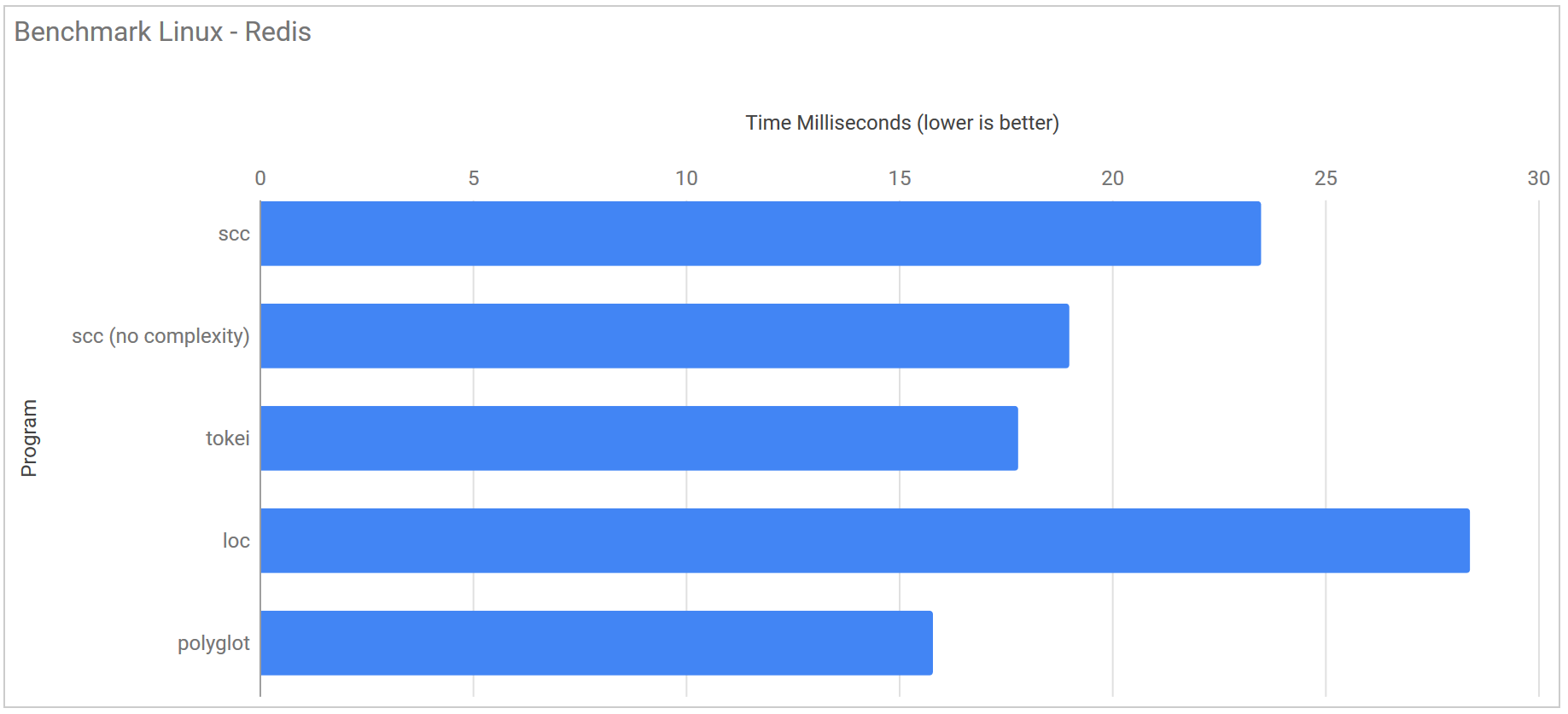
Redis https://github.com/antirez/redis/
| Program | Runtime |
|---|---|
| scc | 23.5 ms ± 2.3 ms |
| scc (no complexity) | 19.0 ms ± 2.3 ms |
| tokei | 17.8 ms ± 2.7 ms |
| loc | 28.4 ms ± 24.9 ms |
| polyglot | 15.8 ms ± 1.2 ms |
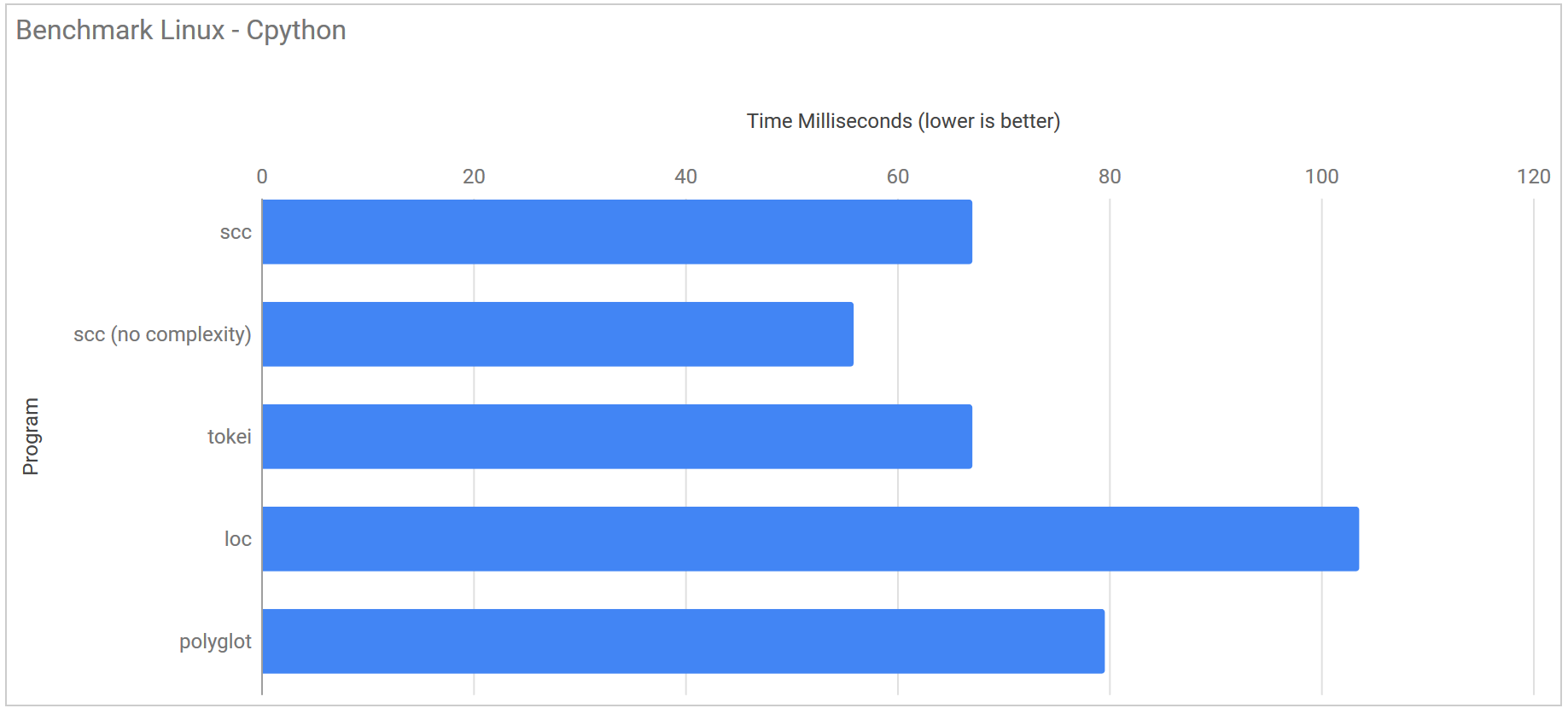
CPython https://github.com/python/cpython
| Program | Runtime |
|---|---|
| scc | 67.1 ms ± 5.2 ms |
| scc (no complexity) | 55.9 ms ± 4.4 ms |
| tokei | 67.1 ms ± 6.0 ms |
| loc | 103.6 ms ± 58.6 ms |
| polyglot | 79.6 ms ± 4.0 ms |
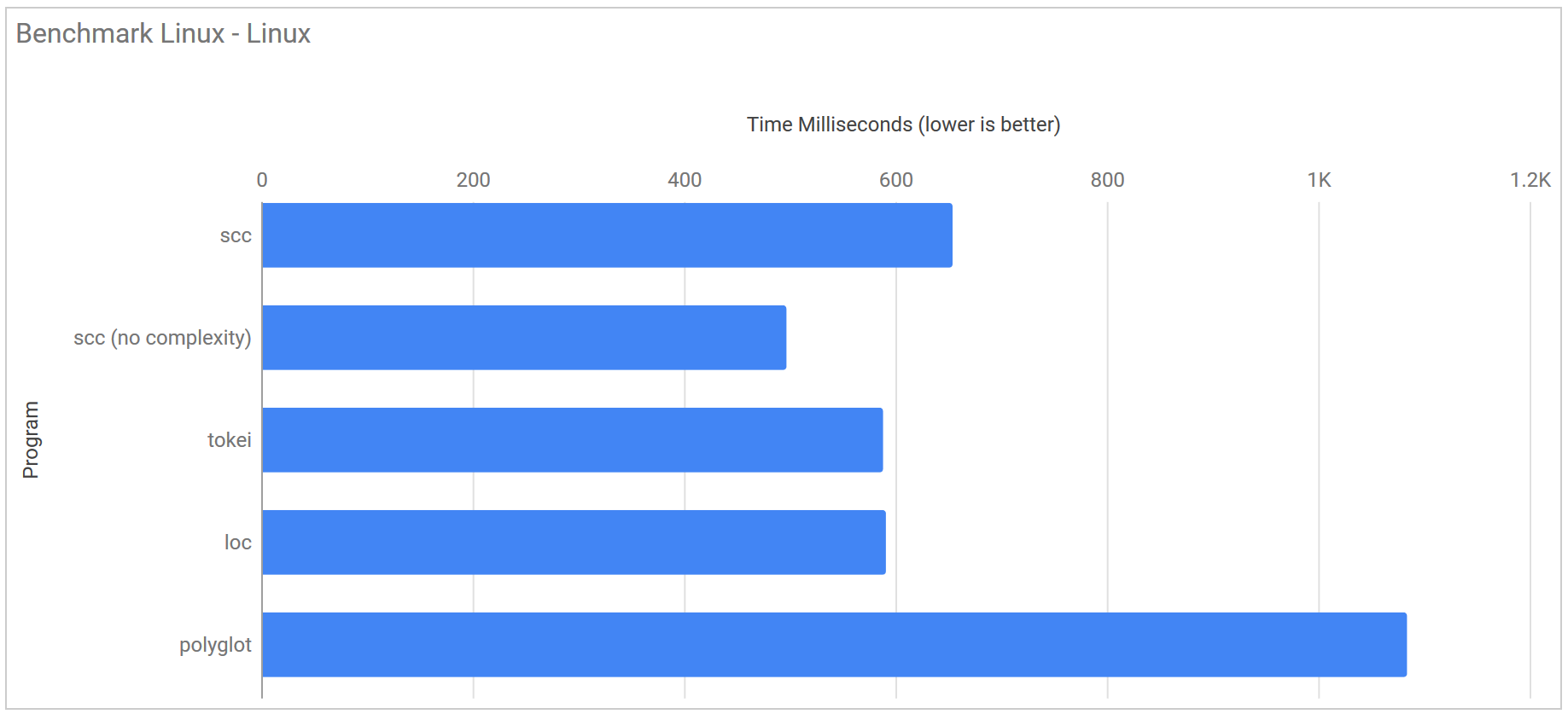
Linux Kernel https://github.com/torvalds/linux
| Program | Runtime |
|---|---|
| scc | 654.1 ms ± 26.0 ms |
| scc (no complexity) | 496.9 ms ± 32.2 ms |
| tokei | 588.3 ms ± 33.4 ms |
| loc | 591.0 ms ± 100.8 ms |
| polyglot | 1.084 s ± 0.051 s |
Linux Kernels
| Program | Runtime |
|---|---|
| scc | 4.979 s ± 0.112 s |
| scc (no complexity) | 3.571 s ± 0.026 s |
| tokei | 5.336 s ± 0.166 s |
| loc | 5.459 s ± 0.348 s |
| polyglot | 7.967 s ± 0.606 s |
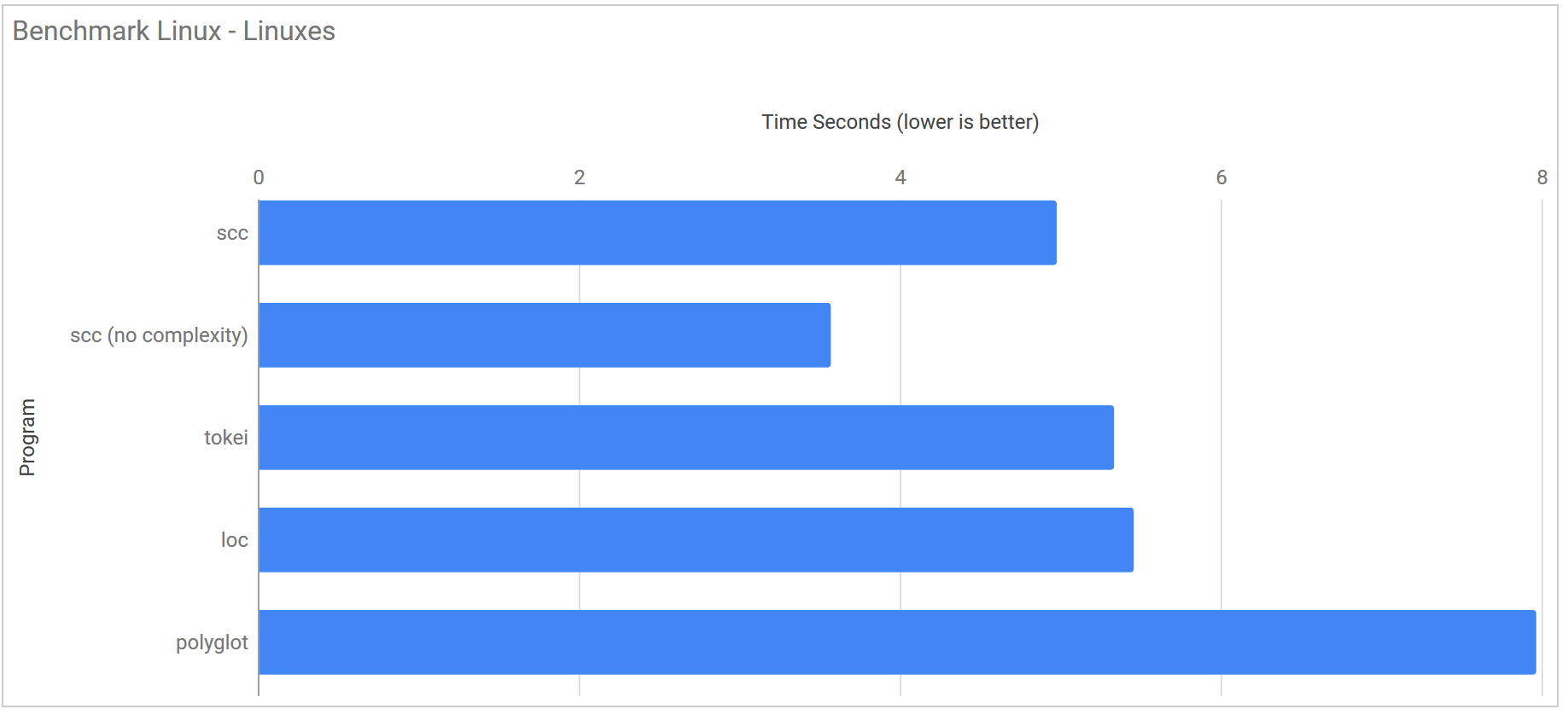
Times are still a little off when it comes to very small repositories such as redis, but considering there is only 6 ms in I would still count things as a massive win. Generally though the improvement makes scc as fast even with complexity calculations or faster without then all other tools for pretty much every case. A pretty nice improvement for a few hours work.
You can get scc on github https://github.com/boyter/scc